Word2Vec2Graph Model and Free Associations
Word2Vec2Graph technique to find text topics is similar to Free Association technique used in psychoanalysis: "The importance of free association is that the patients spoke for themselves, rather than repeating the ideas of the analyst; they work through their own material, rather than parroting another's suggestions" (Freud).
In this post we will show some examples that prove this analogy. As a text file we will use data about Psychoanalysis from Wikipedia.
Read and Clean Psychoanalysis Data File
Read Psychoanalysis Data file, tokenize and remove stop words:import org.apache.spark.ml._
import org.apache.spark.ml.feature._
val inputPsychoanalysis=sc.textFile("/FileStore/tables/psychoanalisys1.txt").
toDF("charLine")
val tokenizer = new RegexTokenizer().
setInputCol("charLine").
setOutputCol("value").
setPattern("[^a-z]+").
setMinTokenLength(5).
setGaps(true)
val tokenizedPsychoanalysis = tokenizer.
transform(inputPsychoanalysis)
val remover = new StopWordsRemover().
setInputCol("value").
setOutputCol("stopWordFree")
val removedStopWordsPsychoanalysis = remover.
setStopWords(Array("none","also","nope","null")++
remover.getStopWords).
transform(tokenizedPsychoanalysis)
Explode Psychoanalysis word arrays to words:
import org.apache.spark.sql.functions.explode
val slpitCleanPsychoanalysis = removedStopWordsPsychoanalysis.
withColumn("cleanWord",explode($"stopWordFree")).
select("cleanWord").
distinct
slpitCleanPsychoanalysis.count//--4030
Are Word Pairs in Trained Word2Vec Model?
Read trained Word2Vec model that was trained and described in our first post.import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml._
import org.apache.spark.ml.feature.Word2VecModel
import org.apache.spark.sql.Row
val word2vec= new Word2Vec().
setInputCol("value").
setOutputCol("result")
val modelNewsWiki=Word2VecModel.
read.
load("w2vNewsWiki")Get a set of all words from the Word2Vec model and compare Psychoanalysis file word pairs with words from the Word2Vec model
val cleanPsychoW2V=slpitCleanPsychoanalysis.
join(modelWords,'cleanWord==='word).
select("cleanWord").
distinct
cleanPsychoW2V.count//--3318The Word2Vec model was trained on corpus based on News and Wikipedia data about psychology but only 82% of Psychoanalysis file word pairs are in the model. To increase this percentage we will include Psychoanalysis file data to training corpus and retrain the Word2Vec model.
Retrain Word2Vec Model
val inputNews=sc.
textFile("/FileStore/tables/newsTest.txt").
toDF("charLine")
val inputWiki=sc.textFile("/FileStore/tables/WikiTest.txt").
toDF("charLine")
val tokenizedNewsWikiPsychoanalysis = tokenizer.
transform(inputNews.
union(inputWiki).
union(inputPsychoanalysis))
val w2VmodelNewsWikiPsychoanalysis=word2vec.
fit(tokenizedNewsWikiPsychoanalysis)
w2VmodelNewsWikiPsychoanalysis.
write.
overwrite.
save("w2VmodelNewsWikiPsychoanalysis")
val modelNewsWikiPsychoanalysis=Word2VecModel.
read.
load("w2VmodelNewsWikiPsychoanalysis") Get a set of all words from the new Word2Vec model and compare them with Psychoanalysis file words:
val modelNewsWikiPsychoanalysis=Word2VecModel.
read.
load("w2VmodelNewsWikiPsychoanalysis")
val modelWordsPsychoanalysis=modelNewsWikiPsychoanalysis.
getVectors.
select("word","vector")
val cleanPsychoNewW2V=slpitCleanPsychoanalysis.
join(modelWordsPsychoanalysis,'cleanWord==='word).
select("word","vector").
distinct
cleanPsychoNewW2V.count//--3433 This new Word2Vec model works a little bit better: 85% of Psychoanalysis File words are in the model.
How Word Pairs are Connected?
Now we will calculate cosine similarities of words within word pairs. We introduced Word2Vec Cosine Similarity Function in the Word2Vec2Graph model Introduction post.import org.apache.spark.ml.linalg.Vector
def dotVector(vectorX: org.apache.spark.ml.linalg.Vector,
vectorY: org.apache.spark.ml.linalg.Vector): Double = {
var dot=0.0
for (i <-0 to vectorX.size-1) dot += vectorX(i) * vectorY(i)
dot
}
def cosineVector(vectorX: org.apache.spark.ml.linalg.Vector,
vectorY: org.apache.spark.ml.linalg.Vector): Double = {
require(vectorX.size == vectorY.size)
val dot=dotVector(vectorX,vectorY)
val div=dotVector(vectorX,vectorX) * dotVector(vectorY,vectorY)
if (div==0)0
else dot/math.sqrt(div)
}
val cleanPsychoNewW2V2=cleanPsychoNewW2V.
toDF("word2","vector2")
val w2wPsycho=cleanPsychoNewW2V.
join(cleanPsychoNewW2V2,'word=!='word2)
val w2wPsychoCosDF=w2wPsycho.
map(r=>(r.getAs[String](0),r.getAs[String](2),
cosineVector(r.getAs[org.apache.spark.ml.linalg.Vector](1),
r.getAs[org.apache.spark.ml.linalg.Vector](3)))).
toDF("word1","word2","cos")Transform to Pairs of Words
Get pairs of words and explode ngrams:import org.apache.spark.sql.functions.explode
val ngram = new NGram().
setInputCol("stopWordFree").
setOutputCol("ngrams").
setN(2)
val ngramCleanWords = ngram.
transform(removedStopWordsPsychoanalysis)
val slpitNgrams=ngramCleanWords.
withColumn("ngram",explode($"ngrams")).
select("ngram").
map(s=>(s(0).toString,
s(0).toString.split(" ")(0),
s(0).toString.split(" ")(1))).
toDF("ngram","ngram1","ngram2").
filter('ngram1=!='ngram2) val ngramCos=slpitNgrams.
join(w2wPsychoCosDF,'ngram1==='word1 && 'ngram2==='word2)Graph on Word Pairs
Now we can build a graph on word pairs: words will be nodes, ngrams - edges and cosine similarities - edge weights.We will save graph vertices and edges as Parquet to Databricks locations, load vertices and edges and rebuild the same graph.
import org.graphframes.GraphFrame
val graphNodes1=ngramCos.
select("ngram1").
union(ngramCos.select("ngram2")).
distinct.
toDF("id")
val graphEdges1=ngramCos.
select("ngram1","ngram2","cos").
distinct.
toDF("src","dst","edgeWeight")
val graph1 = GraphFrame(graphNodes1,graphEdges1)
graph1.vertices.write.
parquet("graphPsychoVertices")
graph1.edges.write.
parquet("graphPsychoEdges")
val graphPsychoanalysisVertices = sqlContext.read.parquet("graphPsychoVertices")
val graphPsychoanalysisEdges = sqlContext.read.parquet("graphPsychoEdges")
val graphPsychoanalysis = GraphFrame(graphPsychoanalysisVertices, graphPsychoanalysisEdges)Page Rank
Calculate Page Rank:val graphPsychoanalysisPageRank = graphPsychoanalysis.
pageRank.
resetProbability(0.15).
maxIter(11).
run()
display(graphPsychoanalysisPageRank.vertices.
distinct.
sort($"pagerank".desc).
limit(10))
id,pagerank
freud,94.16935233039906
psychoanalysis,30.977656078470016
psychoanalytic,22.478475163400674
theory,16.603352488179016
unconscious,16.420744218061404
patients,13.99147342505276
sexual,13.563442527065638
patient,12.591079870941268
analyst,11.662939169635427
treatment,11.566778056932069Finding Topics
In the previous post we described how to find document topics via Word2Vec2Graph model. We created a function to calculate connected components with cosine similarly and component size parameters and a function to transform subgraph edges to DOT language:import org.apache.spark.sql.DataFrame
def w2v2gConnectedComponents(graphVertices: DataFrame,
graphEdges: DataFrame,
cosineMin: Double, cosineMax: Double,
ccMin: Int, ccMax: Int): DataFrame = {
val graphEdgesSub= graphEdges.
filter('edgeWeight>cosineMin).
filter('edgeWeight<cosineMax)
sc.setCheckpointDir("/FileStore/")
val resultCC = graphSub.
connectedComponents.
run()
val resultCCcount=resultCC.
groupBy("component").
count.
toDF("cc","ccCt")
val sizeCC=resultCC.join(resultCCcount,'component==='cc).
filter('ccCt<ccMax).filter('ccCt>ccMin).
select("id","component","ccCt").distinct
graphEdges.join(sizeCC,'src==='id).
union(graphEdges.join(sizeCC,'dst==='id)).
select("component","ccCt","src","dst","edgeWeight").distinct
}
def roundAt(p: Int)(n: Double): Double = {
val s = math pow (10, p); (math round n * s) / s
}
def component2dot(graphComponents: DataFrame,
componentId: Long, cosineMin: Double, cosineMax: Double): DataFrame = {
graphComponents.
filter('component===componentId).
filter('edgeWeight>cosineMin).
filter('edgeWeight<cosineMax).
select("src","dst","edgeWeight").distinct.
map(s=>("\""+s(0).toString +"\" -> \""
+s(1).toString +"\""+" [label=\""+roundAt(2)(s(2).toString.toDouble)+"\"];")).
toDF("dotLine")
}To select parameters we analyzed cosine similarity distribution.
val weightDistribution=graphPsychoanalysisEdges.
map(s=>(roundAt(2)(s(2).toString.toDouble))).
toDF("cosine1").groupBy("cosine1").count.toDF("cosine1","cosine1Count")
display(weightDistribution.orderBy('cosine1))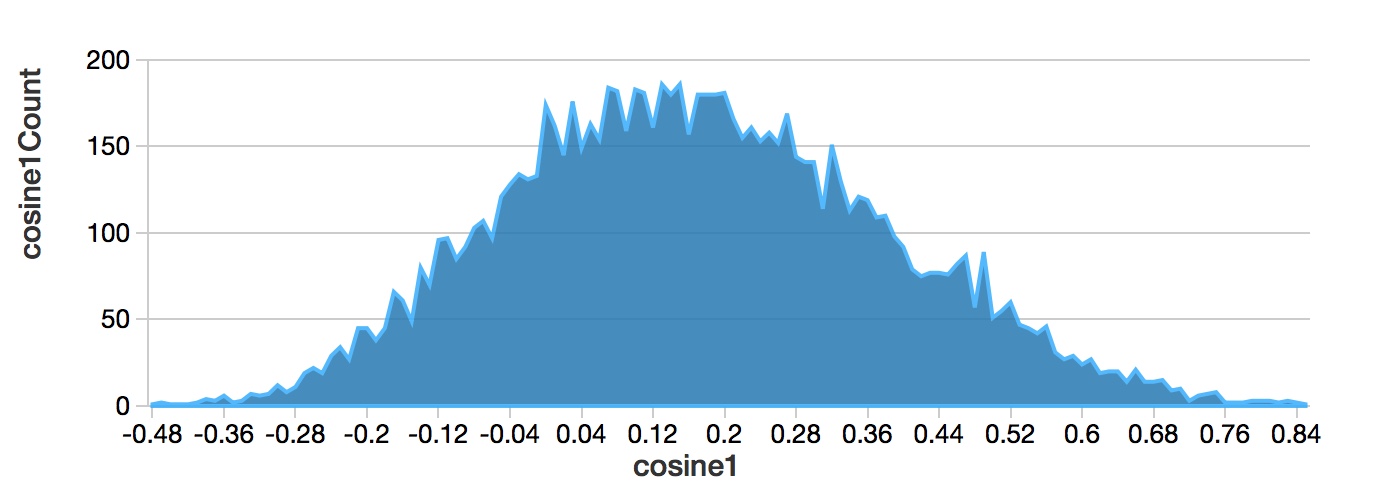
Based on cosine similarity distribution we'll look at topics with high, medium and low cosine similarities.
Psychoanalysis Topics with High Cosine Similarities
Connected components with edge weights greater than 0.7:import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val partitionWindow = Window.
partitionBy($"component").
orderBy($"edgeWeight".desc)
val result=w2v2gConnectedComponents(graphPsychoanalysisVertices,
graphPsychoanalysisEdges,0.7,1.0,3,30)
result.persist
val result3edges = result.
withColumn("rank", rank().over(partitionWindow))
display(result3edges.filter("rank<4").orderBy("component","rank"))
component,ccCt,src,dst,edgeWeight,rank
94489280524,8,patient,symptoms,0.7865587769877727,1
94489280524,8,causes,symptoms,0.7812604197062254,2
94489280524,8,psychological,symptoms,0.7336816137236032,3
103079215116,6,university,professor,0.814475286620036,1
103079215116,6,medicine,university,0.7513358180212253,2
103079215116,6,cornell,university,0.7424065353940977,3
137438953473,7,france,italy,0.8368846158082526,1
137438953473,7,italy,netherlands,0.8187021693660411,2
137438953473,7,italy,switzerland,0.8021272522224945,3
541165879312,5,treatments,therapy,0.8333818545810646,1
541165879312,5,therapy,schizophrenia,0.7847859437652135,2
541165879312,5,behavioral,therapy,0.744693173351612,3We selected component '94489280524'. First we'll create a graph with the same cosine similarity parameters them we used to look at connected components, i.e. for word pairs with cosine similarity >0.7:
val resultDot=component2dot(result,94489280524L,0.7,1.0)
display(resultDot)
"patient" -> "symptoms" [label="0.79"];
"causes" -> "illness" [label="0.7"];
"mental" -> "physical" [label="0.71"];
"causes" -> "symptoms" [label="0.78"];
"psychological" -> "symptoms" [label="0.73"];
"mental" -> "illness" [label="0.73"];
"patient" -> "outcomes" [label="0.72"];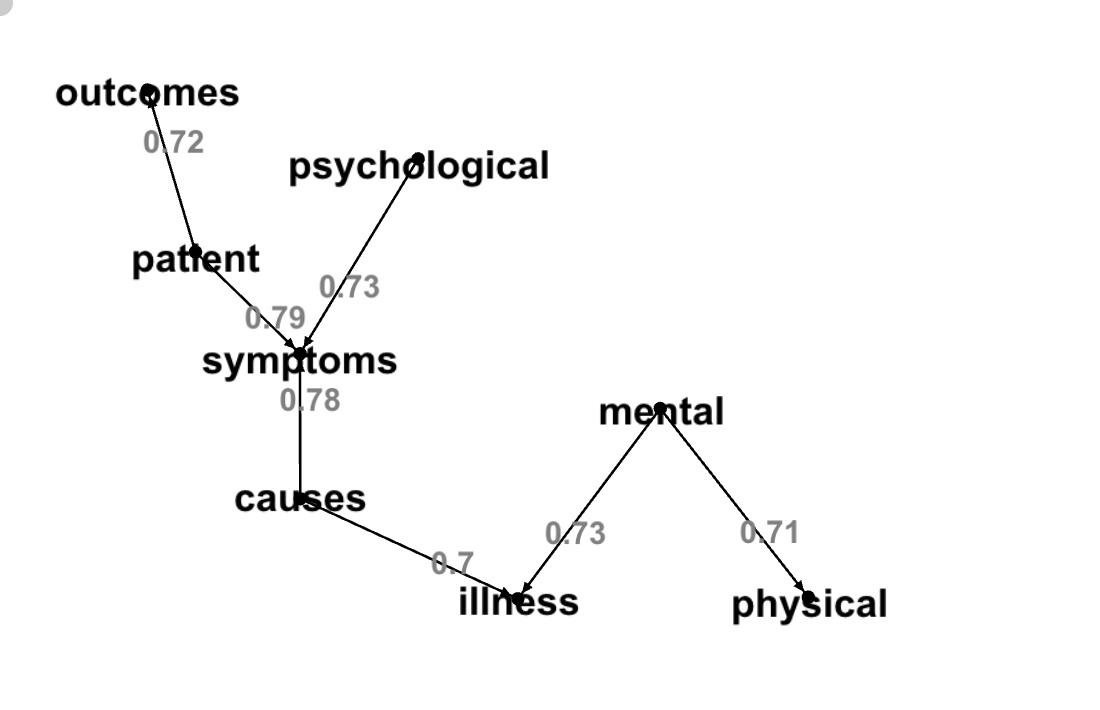
Next we'll expand the topic graph for word pairs with cosine similarity >0.6:

Then we'll expand the same connected component to cosine similarity >0.5:
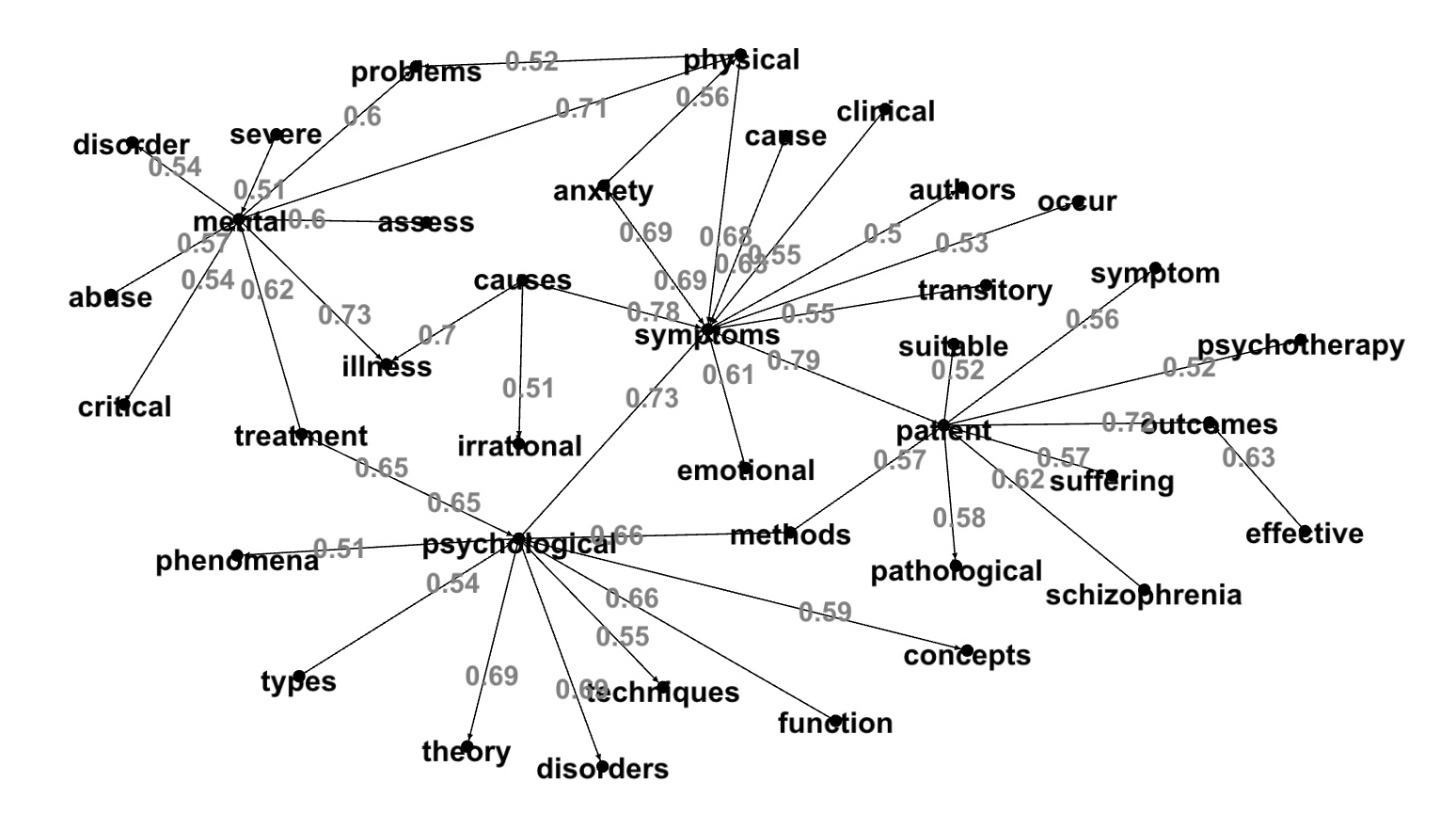
Psychoanalysis Topics with Medium Cosine Similarities
Connected components parameters: edge weights in (0.17, 0.2):Graph picture parameters: edge weights in (0.1, 0.2):

Psychoanalysis Topics with Low Cosine Similarities
Connected components with edge weights in (-0.5, 0.0):Graph picture with no parameters: edge weights in (-1.0, 1.0):
Example 1:
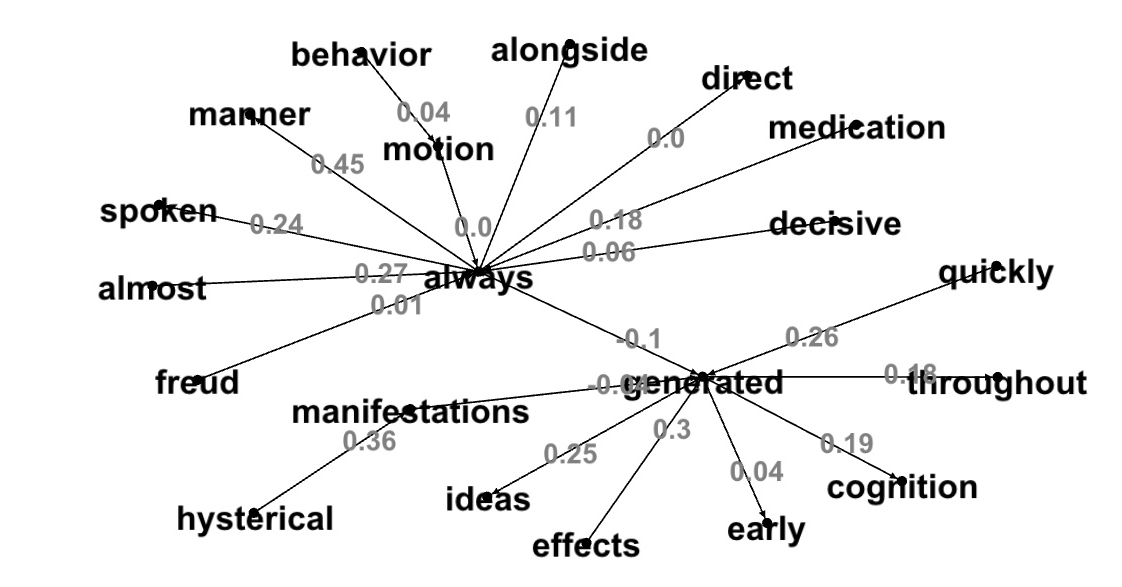
Example 2:
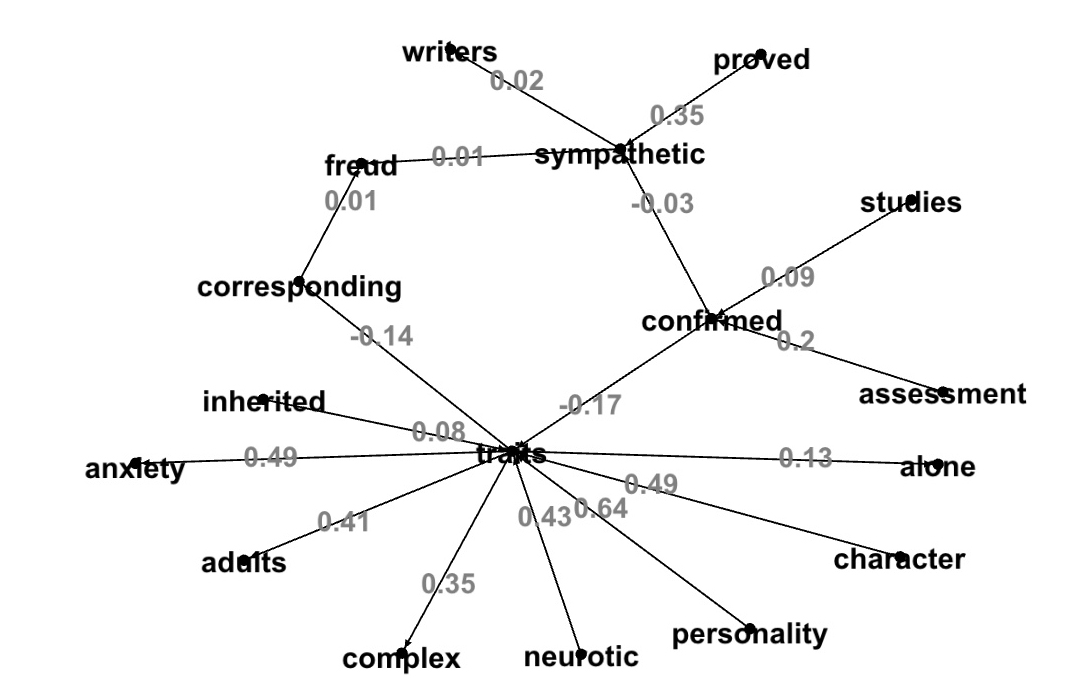
Example 3:

This post example topics with high cosine similarity word pairs are more expected then topics with low cosine similarity word pairs. Lowly correlated word pairs give us more interesting and unpredicted results. The last example shows that within Psychoanalysis text file the word 'association' is associated with some unexpected words...