Word2Vec2Graph Model and New Associations
In our previous post we proved that high cosine similarity text topics are already well known and topics with low cosine similarities give us new associations and new ideas.
In this post we will show another Word2Vec2Graph method to find new word to word associations. This method is similar to psychoanalysis Free Association techniques as well as methods of finding text topics. As a text file in this post we will use data about Creativity and Aha Moments.
We will look at word neighbors using 'find' GraphFrames function that we described in "Word2Vec2Graph Model - Neighbors" post.
Data Preparation
Data preparation process for Word2Vec2Graph model in described in several post and summarized in the "Quick Look at Text" post. Here we used the same data preparation process of text data about Creativity and Aha Moments:- Read text file
- Tokenize
- Remove stop words
- Transform text file to next to each other pairs of words
- Retrain Word2Vec model
- Calculate cosine similarities within pairs of words
- Build a direct graph on pairs of words using words as nodes and cosine similarities as edges weights
- Save graph vertices and edges
Build a Graph
Read graph vertices and edges saved as Parquet to Databricks locations and build the graph for Word2Vec2Graph model.
import org.graphframes.GraphFrame
val graphInsightVertices = sqlContext.read.parquet("graphInsightVertices")
val graphInsightEdges = sqlContext.read.parquet("graphInsightEdges")
val graphInsight = GraphFrame(graphInsightVertices, graphInsightEdges)Page Rank
The highest Page Rank words about Creativity and Aha Moments:
val graphInsightPageRank = graphInsight.
pageRank.resetProbability(0.15).maxIter(11).run()
display(graphInsightPageRank.vertices.
distinct.
sort($"pagerank".desc).limit(12))
id,pagerank
creative,36.427592633298694
brain,35.64966777994186
creativity,26.75614299294646
insight,21.3449149933242
cognitive,20.66552322641501
problem,20.291860811528586
people,18.962734667376907
university,16.66836572882581
social,16.540315233753887
genius,16.250827488029646
knowledge,15.852328556068747
study,15.565795496200513Lines between Words
To see how word pair are connected we will look at 'find' GraphFrames function that we already used in the "Word2Vec2Graph Model - Neighbors" post.
We will start with two high Page Ranks words 'insight' and 'brain' and look for lines of words in both directions.
'insight' -> 'word' -> 'brain':
val path=graphInsight.
find("(a) - [ab] -> (b); (b) - [bc] -> (c)").
filter($"a.id"==="insight").
filter($"c.id"==="brain").
select("a.id","ab.edgeWeight","b.id","bc.edgeWeight","c.id").
toDF("a","ab","b","bc","c")
display(path.orderBy(('ab+'bc).desc))
a,ab,b,bc,c
insight,0.4128722197714052,invasive,0.5830608090075667,brain
insight,0.5926405065153766,creative,0.35538729273722036,brain
insight,0.6265201186962078,solutions,0.13029716155867507,brain
insight,0.20443740746326608,pattern,0.4753597960223179,brain
insight,0.15960073745912792,occur,0.416785760503172,brain
insight,0.32890495067080877,requires,0.19730741846887495,brain
insight,0.11848059507149529,increase,0.1508410859156626,brain
insight,0.10729267923132169,beeman,0.15344660014170144,brain
insight,0.004491484498190776,suggested,0.16421754414027762,brain
insight,-0.043810741336856945,regions,-0.02137437192577632,brain
insight,-0.14634712420947668,along,-0.02381072199458428,brain
insight,-0.13813478755633732,first,-0.1554410765939254,brainval path=graphInsight.
find("(a) - [ab] -> (b); (b) - [bc] -> (c)").
filter($"a.id"==="brain").
filter($"c.id"==="insight").
select("a.id","ab.edgeWeight","b.id","bc.edgeWeight","c.id").
toDF("a","ab","b","bc","c")
display(path.orderBy(('ab+'bc).desc))
a,ab,b,bc,c
brain,0.4486765246697501,conscious,0.22780425594285608,insight
brain,0.30888238508458593,activity,0.2913329808544577,insight
brain,0.1871056077079674,moments,-0.17359890717130036,insight
brain,0.06816500537193591,right,-0.16052900998488828,insightNext we will look for longer lines, i.e. 'word1' -> 'word2' -> 'word3' -> 'word4'. With longer lines the number of word combination is growing fast so we will show only some results.
'insight' -> 'word1' -> 'word2' -> 'brain' (142 lines):
val path=graphInsight.
find("(a) - [ab] -> (b); (b) - [bc] -> (c); (c) - [cd] -> (d)").
filter($"a.id"==="insight").
filter($"d.id"==="brain").
select("a.id","ab.edgeWeight","b.id","bc.edgeWeight","c.id","cd.edgeWeight","d.id").
toDF("a","ab","b","bc","c","cd","d")
display(path.orderBy(('ab+'bc+'cd).desc))
a,ab,b,bc,c,cd,d
insight,0.28168782668396153,brain,0.7644093868324334,cells,0.7644093868324334,brain
insight,0.5873913431733343,creativity,0.72979093470829,creative,0.35538729273722036,brain
insight,0.5873913431733343,creativity,0.3978587884107718,suggests,0.540965758459218,brain
insight,0.0695940003338105,watch,0.2189340241873386,clues,0.4328969882637767,brain
insight,0.23392584234097255,unexpected,0.27952840262,happened,0.202974504974,brain
insight,0.1806737835610359,occurs,0.29306721804427444,various,0.23348013916537874,brain
insight,0.004491484498190776,suggested,0.0039846481446,creative,0.355387292737,brain
iinsight,0.109973700652,analytically,0.091236920188010,increase,0.1508410859156626,brain
insight,0.2537959966753002,flash,0.1505789981661047,across,-0.06288528966788781,brain
'brain' -> 'word1' -> 'word2' -> 'insight' (105 lines):
val path=graphInsight.
find("(a) - [ab] -> (b); (b) - [bc] -> (c); (c) - [cd] -> (d)").
filter($"a.id"==="brain").
filter($"d.id"==="insight").
select("a.id","ab.edgeWeight","b.id","bc.edgeWeight","c.id","cd.edgeWeight","d.id").
toDF("a","ab","b","bc","c","cd","d")
display(path.orderBy(('ab+'bc+'cd).desc))
brain,0.627845334314687,memory,0.5969736849364111,creative,0.5926405065153766,insight
brain,0.5818230817465604,function,0.6050462263809657,creativity,0.5873913431733343,insight
brain,0.522079405363812,abilities,0.6439093697793404,creative,0.5926405065153766,insight
brain,0.2572351478541803,thinking,0.3586918857219751,nature,0.3236593351220391,insight
brain,0.14564507991393688,create,0.4844363325210495,ideas,0.28877305186266056,insight
brain,0.17086866711570267,complex,0.432425015153635,system,0.2989597664441415,insight
brain,0.133737192411332,connections,0.4770965803506682,ideas,0.28877305186266056,insight
brain,0.0695041528304244,fundamental,0.5521335607322843,problem,0.2315418458136853,insight
brain,0.2091917558421882,epiphany,0.4292848059738405,moments,-0.17359890717130036,insight
brain,0.17280034376836279,research,0.04989028618906677,problem,0.2315418458136853,insight
brain,0.07751489118586756,require,0.06005363995904192,spontaneous,0.19017912534928294,insightWord2Vec2Graph Model with Lower Cosine Similarities
In our results we can see than word pairs with high cosine similarity are well known similar words - they are called "synonyms" in Word2Vec model. Pairs of words with lower cosine similarity are more interesting to look at. This is similar to what we showed in our previous post: lower cosine similarity text topics are less known then topics with high cosine similarities.
We will build a graph with lower cosine similarity.
val graphInsightLow = GraphFrame(graphInsightVertices,
graphInsightEdges.filter("edgeWeight<0.33"))
Path String for 'Find' Function
To look at different word-to-word lines we'll start with function that creates a string for 'find' function.
import org.apache.spark.sql.functions._
def formLine(steps:Int): String = {
var line=new String
for (i <- 1 to steps-1) line+="(x"+lit(i)+")-[]->(x"+lit(i+1)+");"
line.substring(0, line.length() - 1)
}Path line examples:
formLine(3)
(x1)-[]->(x2);(x2)-[]->(x3)
formLine(4)
(x1)-[]->(x2);(x2)-[]->(x3);(x3)-[]->(x4)
formLine(5)
(x1)-[]->(x2);(x2)-[]->(x3);(x3)-[]->(x4);(x4)-[]->(x5)'Find' result examples:
val path=graphInsightLow.find(formLine(3))
display(path)
x1,x2,x3
"{""id"":""answers""}","{""id"":""abandon""}","{""id"":""ideas""}"
"{""id"":""according""}","{""id"":""internal""}","{""id"":""goals""}"
"{""id"":""apparent""}","{""id"":""effort""}","{""id"":""takes""}"
"{""id"":""apparent""}","{""id"":""effort""}","{""id"":""achievement""}"
path.printSchema
root
|-- x1: struct (nullable = false)
| |-- id: string (nullable = true)
|-- x2: struct (nullable = false)
| |-- id: string (nullable = true)
|-- x3: struct (nullable = false)
| |-- id: string (nullable = true)
val path=graphInsightLow.find(formLine(4))
x1,x2,x3,x4
"{""id"":""according""}","{""id"":""internal""}","{""id"":""goals""}","{""id"":""chapter""}"
"{""id"":""association""}","{""id"":""brain""}","{""id"":""require""}","{""id"":""spreading""}"
"{""id"":""association""}","{""id"":""brain""}","{""id"":""dominant""}","{""id"":""problem""}"
"{""id"":""according""}","{""id"":""internal""}","{""id"":""goals""}","{""id"":""competitiveness""}"
"{""id"":""according""}","{""id"":""internal""}","{""id"":""goals""}","{""id"":""everyone""}"
path.printSchema
root
|-- x1: struct (nullable = false)
| |-- id: string (nullable = true)
|-- x2: struct (nullable = false)
| |-- id: string (nullable = true)
|-- x3: struct (nullable = false)
| |-- id: string (nullable = true)
|-- x4: struct (nullable = false)
| |-- id: string (nullable = true)
To change the structure of path first we will get a string of words:
val path1=graphInsightLow.find(formLine(4))
val path2=path1.map(s=>(s.toString)).
map(s=>(s.replaceAll("\\[",""))).
map(s=>(s.replaceAll("\\]","")))
display(path2)
value
"according,internal,goals,competitiveness"
"adult,returns,child,interest"
"adult,returns,child,ability"Next we will transform a string of words to array of words:
val path3=path2.map(s=>(s.split(","))).map(s=>(s.toArray))
display(path3)
value
"[""according"",""internal"",""goals"",""competitiveness""]"
"[""adult"",""returns"",""child"",""interest""]"
"[""adult"",""returns"",""child"",""ability""]"Define the Line between Specific Words
Now we can specify words for beginning and end of the path.
val word1="insight"
val word2="brain"
val steps=4
val path4=path3.filter(s=>(s(0).toString==word1)).
filter(s=>(s(steps-1).toString==word2))
display(path4)
value
"[""insight"",""prefrontal"",""activity"",""brain""]"
"[""insight"",""requires"",""different"",""brain""]"
"[""insight"",""depends"",""higher"",""brain""]"
"[""insight"",""depends"",""various"",""brain""]"
"[""insight"",""brain"",""activity"",""brain""]"
"[""insight"",""brain"",""epiphany"",""brain""]"
"[""insight"",""brain"",""creations"",""brain""]"
"[""insight"",""brain"",""active"",""brain""]"
"[""insight"",""believes"",""different"",""brain""]"
"[""insight"",""looking"",""specific"",""brain""]"We can see that in some lines the same word appears several times, for example:
"[""insight"",""brain"",""activity"",""brain""]""Clean Word Duplicates
Explode words within line:
import org.apache.spark.sql.functions.explode
val path5=path4.rdd.zipWithIndex.toDF("words","id").
withColumn("word",explode($"words")).distinct
display(path5.orderBy("id"))
words,id,word
"[""insight"",""prefrontal"",""activity"",""brain""]",0,prefrontal
"[""insight"",""prefrontal"",""activity"",""brain""]",0,insight
"[""insight"",""prefrontal"",""activity"",""brain""]",0,activity
"[""insight"",""prefrontal"",""activity"",""brain""]",0,brain
"[""insight"",""along"",""without"",""brain""]",3,along
"[""insight"",""along"",""without"",""brain""]",3,without
"[""insight"",""along"",""without"",""brain""]",3,brain
"[""insight"",""along"",""without"",""brain""]",3,insight
"[""insight"",""brain"",""connections"",""brain""]",33,connections
"[""insight"",""brain"",""connections"",""brain""]",33,insight
"[""insight"",""brain"",""connections"",""brain""]",33,brainCounts of words within each line:
import org.apache.spark.sql.expressions.Window
val partitionWindow = Window.partitionBy($"id")
val path6 = path5.withColumn("wordCount", count($"word").
over(partitionWindow))
display(path6)
words,id,word
"[""insight"",""prefrontal"",""activity"",""brain""]",0,activity,4
"[""insight"",""prefrontal"",""activity"",""brain""]",0,prefrontal,4
"[""insight"",""prefrontal"",""activity"",""brain""]",0,brain,4
"[""insight"",""prefrontal"",""activity"",""brain""]",0,insight,4
"[""insight"",""along"",""without"",""brain""]",3,without,4
"[""insight"",""along"",""without"",""brain""]",3,insight,4
"[""insight"",""along"",""without"",""brain""]",3,brain,4
"[""insight"",""along"",""without"",""brain""]",3,along,4
"[""insight"",""brain"",""connections"",""brain""]",33,connections,3
"[""insight"",""brain"",""connections"",""brain""]",33,brain,3
"[""insight"",""brain"",""connections"",""brain""]",33,insight,3To exclude line with word duplicates we will filter out lines with count of words smaller then 'steps' - the number of words parameter. If we are calculating circles (like 'brain' -> * -> 'brain' ) we will filter out lines with count of words smaller then 'steps-1':
val result=
if (word1!=word2)path6.filter('wordCount===steps).
select("words","id").distinct
else path6.filter('wordCount===steps-1).
select("words","id").distinctFunction to Find Word Lines
Now we can combine all scripts into function:
import org.apache.spark.sql.DataFrame
def findForm(graph: GraphFrame, word1: String,
word2: String, steps: Int): DataFrame ={
val path1=graph.find(formLine(steps))
val path2=path1.map(s=>(s.toString)).
map(s=>(s.replaceAll("\\[",""))).
map(s=>(s.replaceAll("\\]","")))
val path3=path2.
map(s=>(s.split(","))).
map(s=>(s.toArray))
val path4=path3.
filter(s=>(s(0).toString==word1)).
filter(s=>(s(steps-1).toString==word2))
val path5=path4.rdd.zipWithIndex.
toDF("words","id").
withColumn("word",explode($"words")).distinct
val partitionWindow = Window.partitionBy($"id")
val path6 = path5.withColumn("wordCount",count($"word").
over(partitionWindow))
if (word1!=word2)path6.
filter('wordCount===steps).
select("words","id").distinct
else path6.filter('wordCount===steps-1).
select("words","id").distinct
}Examples
Line: 'insight' -> (1 word) -> 'brain'
display(findForm(graphInsightLow,"brain","insight",3))
words
"[""brain"",""right"",""insight""]"
"[""brain"",""activity"",""insight""]"
"[""brain"",""moments"",""insight""]"Line: 'insight' -> (2 words) -> 'brain' - some examples
display(findForm(graphInsightLow,"brain","insight",4))
words
"[""brain"",""require"",""spontaneous"",""insight""]"
"[""brain"",""thought"",""called"",""insight""]"
"[""brain"",""dominant"",""problem"",""insight""]"
"[""brain"",""response"",""associated"",""insight""]"Line: 'insight' -> (3 words) -> 'brain'
display(findForm(graphInsightLow,"brain","insight",5))
words
"[""brain"",""require"",""neural"",""activity"",""insight""]"
"[""brain"",""dominant"",""problem"",""called"",""insight""]"
"[""brain"",""complex"",""drawing"",""problem"",""insight""]"
"[""brain"",""functions"",""creator"",""ideas"",""insight""]"
"[""brain"",""thinking"",""likely"",""solve"",""insight""]"Circle: 'insight' -> (3 words) -> 'insight'
display(findForm(graphInsightLow,"insight","insight",5))
words
"[""insight"",""requires"",""prefrontal"",""activity"",""insight""]"
"[""insight"",""increase"",""creative"",""moment"",""insight""]"
"[""insight"",""analytically"",""showed"",""associated"",""insight""]"
"[""insight"",""revealed"",""surprising"",""power"",""insight""]"
"[""insight"",""brain"",""activity"",""right"",""insight""]"
"[""insight"",""positive"",""biases"",""conscious"",""insight""]"Circle: 'brain' -> (2 words) -> 'brain'
display(findForm(graphInsightLow,"brain","brain",4))
words
"[""brain"",""right"",""hemisphere"",""brain""]"
"[""brain"",""develop"",""human"",""brain""]"
"[""brain"",""thinking"",""active"",""brain""]"
"[""brain"",""developed"",""different"",""brain""]"
"[""brain"",""involved"",""executive"",""brain""]"Line: 'insight' -> (3 words) -> 'association'
display(findForm(graphInsightLow,"insight","association",5))
words
"[""insight"",""using"",""different"",""sudden"",""association""]"
"[""insight"",""increase"",""creative"",""process"",""association""]"
"[""insight"",""combined"",""social"",""psychological"",""association""]"
"[""insight"",""sometimes"",""analytically"",""sudden"",""association""]"
"[""insight"",""prefrontal"",""circuits"",""process"",""association""]"Circle: 'associated' -> (3 words) -> 'associated'
display(findForm(graphInsightLow,"associated","associated",5))
words
"[""associated"",""different"",""prefrontal"",""activity"",""associated""]"
"[""associated"",""musical"",""ability"",""children"",""associated""]"
"[""associated"",""mental"",""processing"",""music"",""associated""]"
"[""associated"",""specific"",""brain"",""activity"",""associated""]"
"[""associated"",""sustained"",""aerobic"",""activity"",""associated""]"
"[""associated"",""greater"",""knowledge"",""children"",""associated""]"Line: 'association' -> (4 words) -> 'insight'
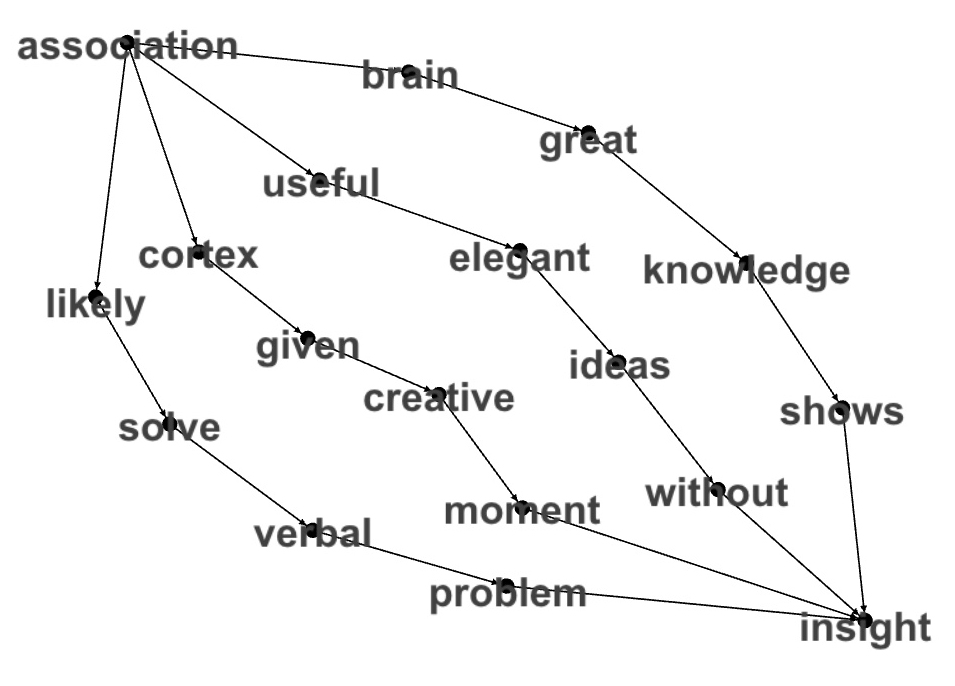
display(findForm(graphInsightLow,"association","insight",6))
words
"[""association"",""useful"",""elegant"",""ideas"",""without"",""insight""]"
"[""association"",""brain"",""great"",""knowledge"",""shows"",""insight""]"
"[""association"",""cortex"",""given"",""creative"",""moment"",""insight""]"
"[""association"",""likely"",""solve"",""verbal"",""problem"",""insight""]"