Rewiring Knowledge Graphs with GNN Link Prediction
2012 marked a pivotal year for the worlds of deep learning and knowledge graphs, setting the stage for innovations that continue to influence their evolution. Among these, the emergence of Convolutional Neural Networks (CNNs) for image classification and the introduction of knowledge graphs by Google were particularly transformative, enhancing data management and paving new paths for semantic analysis.
Graph Neural Networks (GNNs) have since merged the depth of deep learning with the complexity of graph-structured data, enabling sophisticated analyses across various domains—from social networks to bioinformatics. This blend has facilitated advancements in tasks like node classification, link prediction, and overall graph analysis.
In our research, we delve into utilizing GNN Link Prediction to enrich knowledge graphs with textual data, capturing the intricate dynamics of entity relationships often overlooked by attribute-based models. This approach not only unveils latent connections but also refines knowledge graph structures for more nuanced analysis.
In a prior study 'Rewiring Knowledge Graphs by Graph Neural Network Link Predictions' , we focused on rewiring text-based knowledge graphs through the use of GNN link prediction models, specifically targeting semantic knowledge graphs built from text documents. We utilized GNN link prediction techniques to modify these graphs, revealing hidden connections between nodes.
In another study 'Uncovering Hidden Connections: Granular Relationship Analysis in Knowledge Graphs' (2024), we also applied GNN link prediction models to semantic knowledge graphs to uncover hidden relationships within a detailed vector space. We focused on identifying 'graph connectors' that expose deeper network structures and used graph triangle analysis to delve into complex interactions.
The Enron email corpus serves as our testbed, allowing us to explore the potential of text-enhanced knowledge graphs in revealing hidden patterns within organizational communication. By focusing on direct interactions and employing transformer models for text embedding, we lay the groundwork for a knowledge graph that more accurately represents the complexity of real-world relationships.
Our findings underscore the significant impact of incorporating textual data and GNN Link Prediction in knowledge graph analysis. This methodology offers a more comprehensive view of entities' interactions, fostering a deeper understanding of complex networks. As we continue to refine these approaches, the potential for uncovering novel insights in data-rich environments appears boundless, promising exciting avenues for future research.
Key Methodologies of Our Study
In our exploration of enhancing knowledge graphs through GNN Link Prediction, our approach encompasses several pivotal steps:
- Constructing the knowledge graph by leveraging textual interactions between entities to capture the intricacies of their relationships.
- Applying GNN Link Prediction to rewire the knowledge graph, uncovering hidden connections and adding layers to its relational structure.
- Generating node embeddings with a transformer model, transforming textual descriptions into vector forms for a more nuanced analysis.
- Enhancing the knowledge graph's complexity by rewiring it using the DGL GNN Link Prediction model, which incorporates new connections based on predictions to deepen the graph's structure.
Building the Initial Knowledge Graph
The first step in our process is constructing the knowledge graph by thoroughly examining textual interactions between entities. This stage focuses on direct text exchanges to extract crucial elements, forming nodes that capture the core of these interactions. Such a foundation ensures the KG accurately represents the complex relationship network within the data.
Node Embedding
To convert text into vectors, we utilize the 'all-MiniLM-L6-v2' transformer model from Hugging Face. This model efficiently maps text into 384-dimensional vectors, preserving the semantic essence for machine learning applications. This embedding is vital for preparing text within the KG for deep learning analyses like GNN link prediction.
Training the GNN Link Prediction Model
With node embeddings in place, we refine the KG using GNN Link Prediction. This method is crucial for uncovering hidden links, enhancing the KG with a richer interaction spectrum. We use the GraphSAGE link prediction model, leveraging aggregator functions that update node embeddings based on their features and those of adjacent nodes. This model, sourced from the Deep Graph Library (DGL), employs two GraphSAGE layers to update node representations, ensuring a comprehensive reflection of both individual features and network influences.
This integrated approach allows us to delve deeper into the KG, revealing hidden connections and interaction patterns within the data, exemplified by our study on the Enron email dataset.
Experiments Overview
This section outlines the experimental framework used to evaluate our GNN Link Prediction approach in optimizing knowledge graphs, using the Enron email dataset as a case study.
Data Source
The primary data source for our experiments is the Enron email corpus, a comprehensive collection of emails exchanged among executives of the Enron Corporation. This dataset, freely available to the public, captures a wealth of corporate communications, offering a deep dive into the intricacies of a complex organizational network. Its rich detail makes it an excellent resource for our knowledge graph analysis, shedding light on the dynamics of corporate interactions.
The Enron email corpus is hosted on Kaggle, providing easy access for those looking to conduct detailed analyses of the dataset. For further information or to explore the dataset yourself, visit Kaggle's Enron Email Dataset.
Input Data Preparation
We began by creating a knowledge graph from Enron emails from 2000, focusing on internal communications sent from @enron.com addresses. This step involved combining the 'From', 'To', 'Subject', and 'Body' of each email into a unified text block for each node, and linking nodes based on shared senders or recipients to reflect direct communication lines within Enron.
Constructing a Knowledge Graph from Enron's 2000 Email Corpus
Our investigation begins by creating a knowledge graph derived from the Enron email dataset, specifically focusing on the year 2000. Our selection criteria were emails exchanged internally, identifiable through @enron.com addresses, allowing us to concentrate on direct communications between individual employees while excluding group emails for a more targeted analysis.
Node Creation in the Knowledge Graph
To form the nodes of our knowledge graph, we combined the 'From', 'To', 'Subject', and 'Body' of each email into a unified text representation. This approach ensured that each node captured the entirety of an email exchange, preserving both the context and the details of the conversation.
Concatenate 'From', 'To', 'Subject', and 'body' columns with '^' betweendf['emailText'] =
df[['From','To','Subject', 'body']]
.apply(lambda row: ' ^ '.join(row.values.astype(str)), axis=1)unique_emails = pd.concat([df['From'], df['To']]).unique()
email_index = pd.Series(index=unique_emails, data=range(len(unique_emails)), name='emailIdx')
df['FromIdx'] = df['From'].map(email_index)
df['ToIdx'] = df['To'].map(email_index)
emailFromTo=df[['FromIdx','emailTextIdx','emailText', 'ToIdx']]
emailFromTo.tail()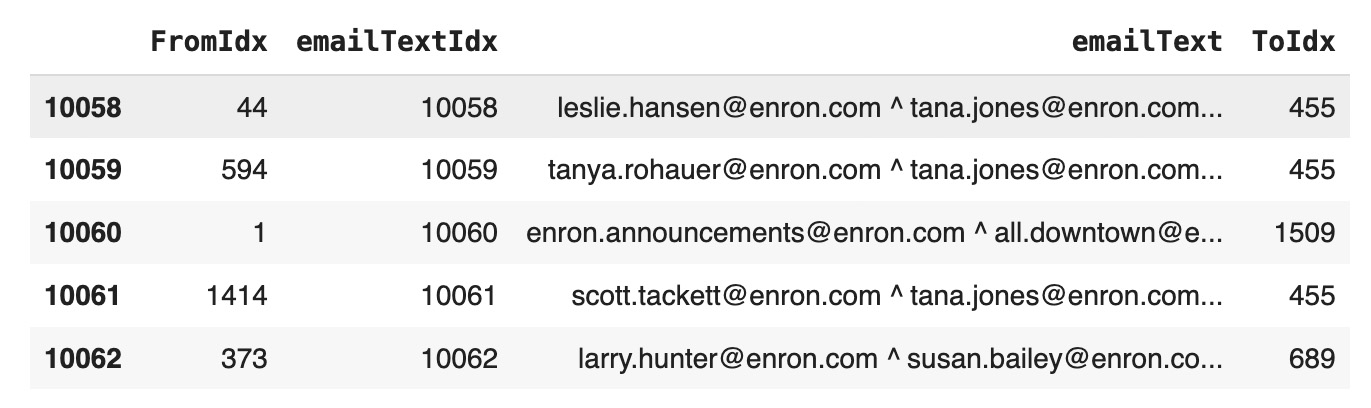
Linking Nodes in the Knowledge Graph
In establishing connections within the knowledge graph, we linked emails sharing common senders or recipients, thereby reflecting a direct communication pathway between entities. This method provided an accurate reflection of how interactions occurred within Enron, uncovering the intricate structure of the network and the dynamic web of relationships between employees.
Self-join emailFromTo table to create edges:df=emailFromTo
joined_df =
df.merge(df, left_on='ToIdx', right_on='FromIdx', suffixes=('_left', '_right'))
df2 = joined_df.query('FromIdx_left != ToIdx_right')
dfLeft = em2text2em[['emailText_left', 'emailTextIdx_left']]
.rename(columns={'emailText_left': 'A', 'emailTextIdx_left': 'idx'})
dfRight = em2text2em[['emailText_right', 'emailTextIdx_right']]
.rename(columns={'emailText_right': 'A', 'emailTextIdx_right': 'idx'})dff=em2text2em
combined_df =
pd.concat([dfLeft, dfRight]).drop_duplicates().reset_index(drop=True)
combined_df = combined_df.sort_values(by='A')
combined_df.reset_index(drop=True, inplace=True)
combined_df['new_index'] = combined_df.index
nodes=combined_df[['new_index','A']]
nodes.tail()  Reindex edges:
Reindex edges:
idx_mapping =
pd.Series(combined_df['new_index'].values, index=combined_df['idx']).to_dict()
dff['new_idxLeft'] = dfLeft['idx'].map(idx_mapping)
dff['new_idxRight'] = dfRight['idx'].map(idx_mapping)
edges=dff[['new_idxLeft','new_idxRight']]
edges=edges.drop_duplicates()
edges.tail() 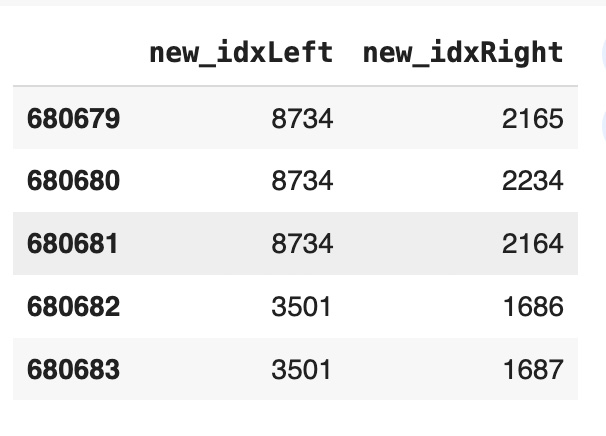
Model Training
The model training phase started with embedding the textual content of emails using the 'all-MiniLM-L6-v2' transformer model. Following this, we trained the GNN Link Prediction model using the Deep Graph Library (DGL) and its GraphSAGE layers to discover new connections within the knowledge graph.
Convert edges to DGL model:unpickEdges=edges
edge_index=torch.tensor(unpickEdges[['new_idxLeft','new_idxRight']].T.values)
u,v=edge_index[0],edge_index[1]
g=dgl.graph((u,v))
g=dgl.add_self_loop(gNew)
g
Graph(num_nodes=9654, num_edges=667354,
ndata_schemes={}
edata_schemes={}) from sentence_transformers import SentenceTransformer
modelST = SentenceTransformer('all-MiniLM-L6-v2')
node_embeddings = modelST.encode(nodes['A'],convert_to_tensor=True)
node_embeddings = node_embeddings.to(torch.device('cpu'))
g.ndata['feat'] = node_embeddings
g
Graph(num_nodes=9654, num_edges=667354,
ndata_schemes={'feat': Scheme(shape=(384,), dtype=torch.float32)}
edata_schemes={}) all_logits = []
for e in range(100):
# forward
h = model(train_g, train_g.ndata['feat'].float())
pos_score = pred(train_pos_g, h)
neg_score = pred(train_neg_g, h)
loss = compute_loss(pos_score, neg_score)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if e % 5 == 0:
print('In epoch {}, loss: {}'.format(e, loss)) 
from sklearn.metrics import roc_auc_score
with torch.no_grad():
pos_score = pred(test_pos_g, h)
neg_score = pred(test_neg_g, h)
print('AUC', compute_auc(pos_score, neg_score))
AUC 0.9673248461572111Rewiring Knowledge Graph
Using GNN Link Prediction, we processed email data into vectors, setting a cosine similarity threshold of 0.95 to update the knowledge graph with strong node pairs. This rewiring process revealed shifts in the network's influencers by comparing top 10 betweenness centrality scores before and after the adjustment, showcasing the model's ability to uncover hidden relationship dynamics and refine the graph's structure.
Cosine Similarities function:
import torch
def pytorch_cos_sim(a: Tensor, b: Tensor):
return cos_sim(a, b)
def cos_sim(a: Tensor, b: Tensor):
if not isinstance(a, torch.Tensor):
a = torch.tensor(a)
if not isinstance(b, torch.Tensor):
b = torch.tensor(b)
if len(a.shape) == 1:
a = a.unsqueeze(0)
if len(b.shape) == 1:
b = b.unsqueeze(0)
a_norm = torch.nn.functional.normalize(a, p=2, dim=1)
b_norm = torch.nn.functional.normalize(b, p=2, dim=1)
return torch.mm(a_norm, b_norm.transpose(0, 1))
cosine_scores_gnn = pytorch_cos_sim(h, h)
pairs_gnn = []
for i in range(len(cosine_scores_gnn)):
for j in range(len(cosine_scores_gnn)):
if i>j:
if cosine_scores_gnn[i][j].detach().numpy() > 0.95:
pairs_gnn.append({'idx1': i,'idx2': j,
'score': cosine_scores_gnn[i][j].detach().numpy()}) import networkx as nx
G = nx.Graph()
edges = df[df['score'] > 0.95][['idx1', 'idx2']]
edges.rename(columns={'idx1': 'source', 'idx2': 'target'}, inplace=True)
G.add_edges_from(edges.values.tolist()) betweenness_rewired = nx.betweenness_centrality(G1)
top_rewired = sorted(betweenness_rewired.items(), key=lambda x: x[1], reverse=True)[:10]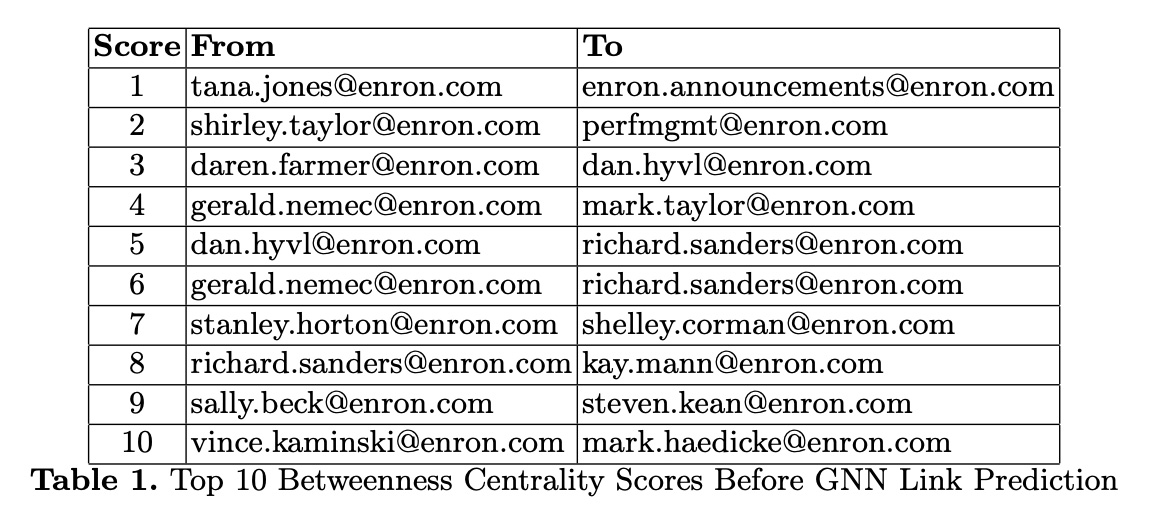
We chose betweenness centrality to identify key influencers in our knowledge graph because it shows how nodes connect others by acting as information bridges. High betweenness scores highlight nodes crucial for spreading information across the network.
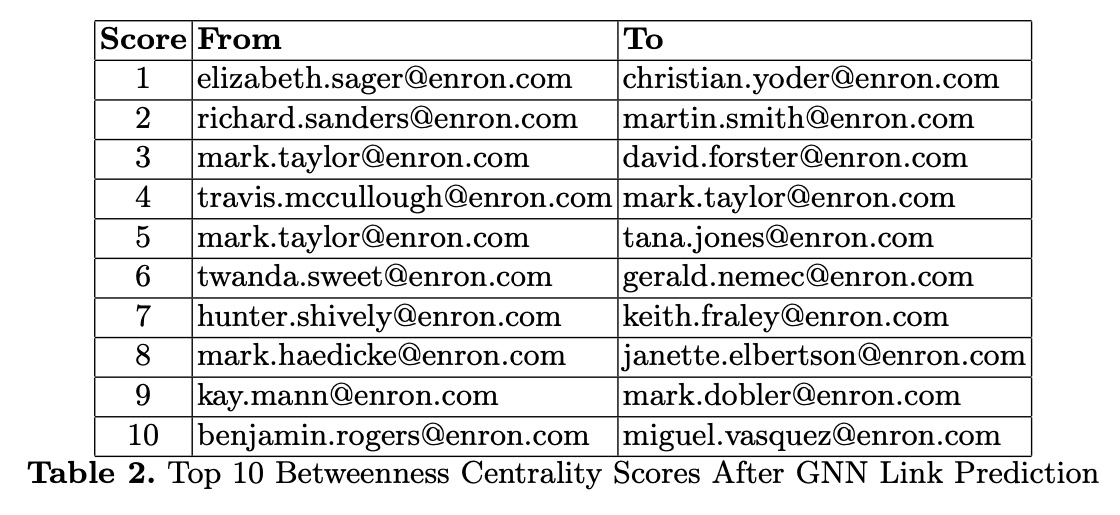 Before and after applying the GNN Link Prediction model, as evidenced in Tables 1 and 2, we observed shifts in betweenness centrality scores. Initially, the graph's links were formed strictly from direct email interactions, based on sender and recipient information. However, after the rewiring process, we expanded our criteria to include the emails' content, such as the 'Subject' and 'Body'. This approach added a new layer of depth to the graph, creating richer connections that reflect the substantive content of the communications.
Before and after applying the GNN Link Prediction model, as evidenced in Tables 1 and 2, we observed shifts in betweenness centrality scores. Initially, the graph's links were formed strictly from direct email interactions, based on sender and recipient information. However, after the rewiring process, we expanded our criteria to include the emails' content, such as the 'Subject' and 'Body'. This approach added a new layer of depth to the graph, creating richer connections that reflect the substantive content of the communications.