Read Word Pairs Graph
In the previous post we built and saved Word2Vec2Graph for pair of words of Stress Data file. In this post we will look for connected word pair groups using Spark GraphFrames library functions: Connected Components and Label Propagation.
Read stored vertices and edges and rebuilt the graph:
import org.graphframes.GraphFrame
val graphNgramStressVertices = sqlContext.read.parquet("graphNgramVertices")
val graphNgramStressEdges = sqlContext.read.parquet("graphNgramEdges")
val graphNgramStress = GraphFrame(graphNgramStressVertices, graphNgramStressEdges)
Connected Components
sc.setCheckpointDir("/FileStore/")
val resultStressCC = graphNgramStress.
connectedComponents.
run()
val ccStressCount=resultStressCC.
groupBy("component").
count.
toDF("cc","ccCt")
display(ccStressCount.orderBy('ccCt.desc))
cc,ccCt
0,1111
240518168576,2As we could expect, almost all word pairs are connected therefore almost alls of them are in the same large connected component.
When we looked at all word to word combinations from text file, pairs of words were tightly connected and we could not split them to separate groups. Now looking at ngram word pairs we can use community detection algorithms to split them to word pair groups. We'll start with the simplest community detection algorithm - Label Propagation.
Label Propagation
val lapelPropId = graphNgramStress.
labelPropagation.
maxIter(5).
run().
toDF("lpWord","lpLabel")
display(lapelPropId.
groupBy("lpLabel").count.toDF("label","count").
orderBy('count.desc).limit(11))
label,count
386547056642,115
317827579910,107
515396075520,26
420906795012,22
274877906949,19
738734374914,12
481036337155,10
1382979469314,10
575525617667,10
188978561028,9
927712935936,9
As Label Propagation algorithm is cutting loosely connected edges, we want to see which {word1, word2} ngram pairs from text file are within the same Label Propagation groups.
val pairLabel=graphNgramStress.
edges.
join(lapelPropId,'src==='lpWord).
join(lapelPropId.toDF("lpWord2","lpLabel2"),'dst==='lpWord2).
filter('lpLabel==='lpLabel2).
select('src,'dst,'edgeWeight,'lpLabel)
For now we will ignore small groups and look at groups that have at least 3 {word1, word2} pairs.
display(pairLabel.
groupBy("lpLabel").count.toDF("lpLabelCount","pairCount").
filter("pairCount>2").orderBy('pairCount.desc))
lpLabelCount,pairCount
386547056642,54
317827579910,30
274877906949,8
Word Pair Groups
We'll start with the second group - group that contains 30 {word1, word2} pairs. Here are edges that belong to this group - {word1, word2, word2vec cosine similarity}:
display(pairLabel.
filter('lpLabel==="317827579910").
select('src,'dst,'edgeWeight).
orderBy('edgeWeight.desc))
src,dst,edgeWeight
military,combat,0.6585100225253417
theories,kinds,0.614683170553027
greatly,affect,0.5703911227199971
individual,susceptible,0.5092298863558692
individual,indirectly,0.50178581898798
changes,affect,0.44110535802060397
individual,examples,0.435892677464733
individual,either,0.4149070407876195
requires,individual,0.4125513014023833
affect,individual,0.3983243027379392
individual,better,0.38429278796103433
individual,perceive,0.3798804220663263
individual,experience,0.36348468757986896
cause,changes,0.35436057661804354
indirectly,deals,0.33550190287381315
prevention,requires,0.3049172137994746
displacement,individual,0.2841213622282649
better,negative,0.2451413181091326
individual,diminished,0.23837691546795897
cause,either,0.22592468033966373
humor,individual,0.221442007247884
individual,personality,0.20933309402530506
affect,promoting,0.19505527986421928
cause,individual,0.18144254665538492
changes,caused,0.15654198248664133
experience,conflicting,0.14323076298532875
individual,level,0.09802076461154222
level,combat,0.0915599285372975
causing,individual,0.008010528297421033
individual,takes,0.0017983474881583593Graph (via Gephi):
 We use a semi-manual way on building Gephi graphs. Create a list of direct edges:
We use a semi-manual way on building Gephi graphs. Create a list of direct edges:
display(pairLabel.
filter('lpLabel==="317827579910").
map(s=>(s(0).toString + " -> "+ s(1).toString)))
Then put the list within 'digraph{...}' and getting data in .DOT format:
digraph{p>
level -> combat
military -> combat
changes -> caused
indirectly -> deals
requires -> individual
displacement -> individual
cause -> individual
humor -> individual
causing -> individual
affect -> individual
individual -> examples
experience -> conflicting
individual -> either
cause -> either
individual -> susceptible
individual -> experience
individual -> better
individual -> personality
affect -> promoting
individual -> perceive
individual -> diminished
theories -> kinds
changes -> affect
greatly -> affect
individual -> level
individual -> indirectly
cause -> changes
individual -> takes
better -> negative
prevention -> requires
}Here is the graph for the group of 54 pair. 'Stress' - the word with the highest PageRank is in the center of this graph:

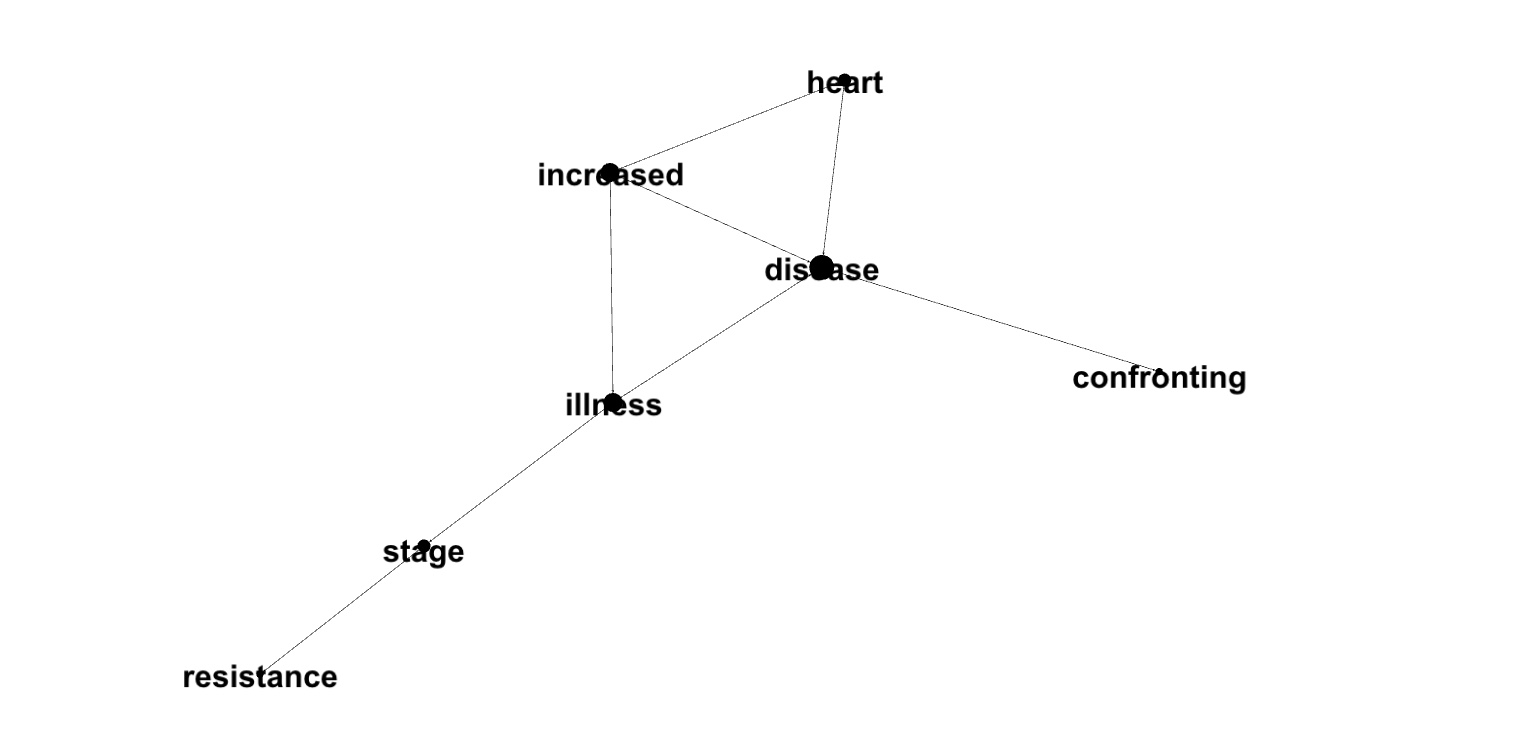
Here is the graph for the group of 8 pair:
High Topics of Label Groups
We can see that in the center of the biggest group is the word 'stress' - the word with the highest PageRank. We'll calculate high PageRank words for word pair groups. Calculate PageRank:val graphNgramStressPageRank =
graphNgramStress.
pageRank.
resetProbability(0.15).
maxIter(11).
run()
val pageRankId=graphNgramStressPageRank.
vertices.
toDF("prWord","pagerank")Calculate lists of distinct words in the label groups:
val wordLabel=pairLabel.
select('src,'lpLabel).
union(pairLabel.
select('dst,'lpLabel)).
distinct.
toDF("lpWord","lpLabel")
display(wordLabel.
groupBy('lpLabel).count.
toDF("lpLabel","labelCount").
filter("labelCount>2").
orderBy('labelCount.desc))
lpLabel,labelCount
386547056642,47
317827579910,30
274877906949,7
146028888068,4
1675037245443,3Top 10 Words in Label Groups
The biggest group:
val wordLabelPageRank=wordLabel.
join(pageRankId,'lpWord==='prWord).
select('lpLabel,'lpWord,'pageRank)
display(wordLabelPageRank.
select('lpWord,'pageRank).
filter('lpLabel==="386547056642").
orderBy('pageRank.desc).
limit(10))
lpWord,pageRank
stress,36.799029843873036
stressful,7.982561760153138
anxiety,5.280935662282566
levels,3.577601059501528
depression,2.997965863478802
cognitive,2.4835377323499968
event,2.376589797720234
system,2.209925145397034
physiological,2.010263387749949
laughter,1.9427846994029507Second group:
display(wordLabelPageRank.
select('lpWord,'pageRank).
filter('lpLabel==="317827579910").
orderBy('pageRank.desc).
limit(10))
lpWord,pageRank
individual,8.75686668967628
changes,5.642126628136839
negative,3.89748211412626
affect,2.869162036449995
cause,2.82449665904923
humor,2.654039734715573
either,2.629897237315239
examples,2.2158219523034477
experience,2.086137279362367
level,1.7538722184950524Third Group:
display(wordLabelPageRank.
select('lpWord,'pageRank).
filter('lpLabel==="274877906949").
orderBy('pageRank.desc).
limit(10))
lpWord,pageRank
disease,4.195635531226847
illness,2.90222622174496
heart,2.1357113367905662
increased,1.4318340158498353
stage,1.0047304801814618
resistance,0.8456856157412355
confronting,0.6327411341532586Comparing group graphs with PageRanks of words within groups shows that the words with high PageRanks are located in graph center.