Word2Vec2Graph Model and Connections
In this post we will show how to use Word2Vec2Graph to better understand connections between the words in text files. As text file we will use a combination of text files from previous posts: Stress text file, Psychoanalysis text file, and Creativity and Aha Moments text file. All three text files were related to brain and we will call a new text file Brain Text File.
Building Word2Vec2Graph Model
To build the Word2Vec2Graph model in this post we will use slightly different data preparation process than the process that was described in the "Quick Look at Text" post:- Read text files and combine the data to Brain Text File
- Tokenize
- Remove stop words
- Within each line of Brain Text File get trios of words: (word1, word2, word3)
- Get list of all words from trios of words
- Combine Brain Text File with News Text File and train Word2Vec model
- Calculate cosine similarities for all pairs of words from trios of words
- Build a direct graph on trios of words using word1 and word3 as nodes and word2 and cosine similarities between word1 and word3 as edges attributes
- Save graph vertices and edges
Data Preparation
Combine text files about stress, psychoanalysis and aha moments.
val inputStress=sc.
textFile("/FileStore/tables/stressWiki.txt").
toDF("charLine")
val inputPsychoanalysis=sc.
textFile("/FileStore/tables/psychoanalisys1.txt").
toDF("charLine")
val inputInsight=sc.
textFile("/FileStore/tables/ahaMoments.txt").
toDF("charLine")
val inputBrain=inputStress.
union(inputPsychoanalysis).
union(inputInsight)
inputBrain.count//--2422Tokenize text file and exclude stop words:
import org.apache.spark.ml._
import org.apache.spark.ml.feature._
val tokenizer = new RegexTokenizer().
setInputCol("charLine").
setOutputCol("value").
setPattern("[^a-z]+").
setMinTokenLength(5).
setGaps(true)
val tokenizedInput = tokenizer.
transform(inputBrain)
val remover = new StopWordsRemover().
setInputCol("value").
setOutputCol("stopWordFree")
val removedStopWordsInput = remover.
setStopWords(Array("none","also","nope","null")++
remover.getStopWords).
transform(tokenizedInput)Get word trios (word1, word2, word3) from lines of inputBrain text file:
val ngramTrio = new NGram().
setInputCol("stopWordFree").
setOutputCol("ngrams").
setN(3)
val ngramTrioCleanWords = ngramTrio.
transform(removedStopWordsInput)Explode word trios:
import org.apache.spark.sql.functions.explode
val slpitNgramsTrio=ngramTrioCleanWords.
withColumn("ngram",explode($"ngrams")).select("ngram").distinct.toDF("trioWords")
display(slpitNgramsTrio.limit(10))
trioWords
differently experiences different
humor excellent defensive
behavior brain science
women exist unfair
stress desired beneficial
salaried entitled lectures
journals pared people
family balance women
kinds stress stress
stress helps improveSplit word trios to three columns:
val brainTrioWords=slpitNgramsTrio.
map(s=>(s(0).toString,
s(0).toString.split(" ")(0),
s(0).toString.split(" ")(1),
s(0).toString.split(" ")(2))).
toDF("trioWords","word1","word2","word3").
filter('word1=!='word2).filter('word1=!='word3).filter('word2=!='word3)
display(brainTrioWords.limit(10))
trioWords,word1,word2,word3
negative emotions surrounding,negative,emotions,surrounding
longer periods types,longer,periods,types
enhancement markers natural,enhancement,markers,natural
individual differences vulnerability,individual,differences,vulnerability
inherently neutral meaning,inherently,neutral,meaning
events occurred within,events,occurred,within
however positive experiences,however,positive,experiences
traits whether attend,traits,whether,attend
grade stressors background,grade,stressors,background
typical examples ambient,typical,examples,ambientGet the list of all words from word trios:
val brainAllWords=brainTrioWords.select("word1").
union(brainTrioWords.select("word2")).
union(brainTrioWords.select("word3")).
distinct.toDF("wordList")
display(brainAllWords.limit(10))
wordList
recognize
persist
everyday
still
connected
interaction
travel
safeguarding
noncaregivers
enhancementTrain Word2Vec Model
Combine News Text File and Brain Text File for Word2Vec model:
import org.apache.spark.ml._
import org.apache.spark.ml.feature.Word2VecModel
import org.apache.spark.sql.Row
val inputNews=sc.
textFile("/FileStore/tables/newsTest.txt").
toDF("charLine")
val tokenizedNewsBrain = tokenizer.
transform(inputNews.
union(inputBrain))Train Word2Vec model and save the results:
val word2vec= new Word2Vec()
.setInputCol("value")
.setOutputCol("result")
val w2Vmodel=word2vec.
fit(tokenizedNewsBrain)
w2Vmodel.
write.
overwrite.
save("w2VmodelNewsBrain")
val modelNewsBrain=Word2VecModel.
read.
load("w2VmodelNewsBrain")
display(modelNewsBrain.findSynonyms("creativity",7))
word,similarity
diversity,0.8130543231964111
compatible,0.8086180090904236
functions,0.7818686366081238
relationships,0.7691928148269653
mechanisms,0.7640953063964844
environments,0.7629551887512207
expertise,0.7596272230148315Get a set of all words from the modelNewsBrain Word2Vec model and join them with list of words from Brain Text File:
val modelWordsBrain=modelNewsBrain.
getVectors.
select("word","vector")
val brainWordVector=brainAllWords.
join(modelWordsBrain,'wordList==='word).
select("word","vector").
distinct
brainWordVector.count//--7794Cosine Similarities
Cosine similarity function:
import org.apache.spark.ml.linalg.Vector
def dotVector(vectorX: org.apache.spark.ml.linalg.Vector,
vectorY: org.apache.spark.ml.linalg.Vector): Double = {
var dot=0.0
for (i <-0 to vectorX.size-1) dot += vectorX(i) * vectorY(i)
dot
}
def cosineVector(vectorX: org.apache.spark.ml.linalg.Vector,
vectorY: org.apache.spark.ml.linalg.Vector): Double = {
require(vectorX.size == vectorY.size)
val dot=dotVector(vectorX,vectorY)
val div=dotVector(vectorX,vectorX) * dotVector(vectorY,vectorY)
if (div==0)0
else dot/math.sqrt(div)
}Self-join brainWordVector table to get all pairs of words of Brain Text File:
val brainWordVector2=brainWordVector.
toDF("word2","vector2")
val w2wBrain=brainWordVector.
join(brainWordVector2,'word=!='word2).
select("word","vector","word2","vector2")
w2wBrain.count//--60738642Calculate Cosine Similarity matrix - Cosine Similarities between all pairs of words of Brain Text File:
val w2wBrainCosMatrix=w2wBrain.
map(r=>(r.getAs[String](0),r.getAs[String](2),
cosineVector(r.getAs[org.apache.spark.ml.linalg.Vector](1),
r.getAs[org.apache.spark.ml.linalg.Vector](3)))).
toDF("w1","w2","cos12")Build a Graph
To prepare word triples for graph we will join Brain Text File triples (brainTrioWords table) with cosine similarity matrix:
val trioCos=brainTrioWords.
join(w2wBrainCosMatrix, 'word1==='w1 && 'word3==='w2).
select("word1", "word3", "word2", "cos12")Build a graph:
import org.graphframes.GraphFrame
val graphNodes1=trioCos.
select("word1").
union(trioCos.select("word2")).
distinct.
toDF("id")
val graphEdges1=trioCos.
select("word1","word3","word2","cos12").
distinct.
toDF("src","dst","edgeName","edgeWeight")
val graph1 = GraphFrame(graphNodes1,graphEdges1)Save graph vertices and edges as Parquet to Databricks locations:
graph1.vertices.write.
parquet("graphBrainVertices")
graph1.edges.write.
parquet("graphBrainEdges")Load vertices and edges and rebuild the same graph:
val graphBrainVertices = sqlContext.read.parquet("graphBrainVertices")
val graphBrainEdges = sqlContext.read.parquet("graphBrainEdges")
val graphBrain = GraphFrame(graphBrainVertices, graphBrainEdges)Graph PageRank:
val graphBrainPageRank = graphBrain.
pageRank.
resetProbability(0.15).
maxIter(11).run()
display(graphBrainPageRank.vertices.
distinct.sort($"pagerank".asc).limit(11))
id,pagerank
freud,74.31134249545481
brain,38.13756389088785
creative,35.10291570480231
creativity,30.94055809189146
insight,25.806952787055366
psychoanalysis,25.514027656136673
stress,24.445974901156116
theory,23.87317685853816
problem,23.737729501554316
cognitive,22.80768036272832
people,21.44400068476515With the exception of the word 'Freud' the word 'Brain' is the most popular word in our Brain Text File.
Statistics for Edge Name and Edge Weight
Calculate stats for Edge Weights and Edge Names:
import org.apache.spark.sql.functions._
import org.apache.spark.sql.functions._
val edgesStats=graphBrain.edges.
groupBy("edgeName").agg(max("edgeWeight").alias("max"),
min("edgeWeight").alias("min"),
sum("edgeWeight").alias("sum"),
count("edgeWeight").alias("count")).filter("count>1")Highest edge weights:
display(edgesStats.orderBy('max.desc).limit(7))
edgeName,max,min,sum,count
child,0.8584717249492438,-0.30117121433417127,7.583085681939111,54
psychology,0.8556911081737578,-0.37700439365336214,9.712497328132436,55
professor,0.83394840981085,-0.06342301939331417,5.958904858793974,19
global,0.8335144633411368,0.03901084757412033,1.927672549812371,5
accomplished,0.8329918442983587,0.02458739411403451,0.8575792384123933,2
austria,0.8320654816237527,0.02353840399552282,1.18496342567388,4
cause,0.82675033228016,-0.1281579124896022,4.965468953366158,22Lowest edge weights:
display(edgesStats.orderBy('min.asc).limit(7))
edgeName,max,min,sum,count
beeman,0.596008130136649,-0.5696883342362257,4.134895812880752,33
distinctive,0.36268952837900825,-0.5584905988347715,-0.5268212152607737,4
structure,0.5352828171045373,-0.533270758587534,2.0451058016988632,17
prefrontal,0.6457235466765552,-0.5218483665866732,3.4488260817462293,69
suggest,0.6282606822240733,-0.5171839101516457,3.0008698422837994,21
cingulate,0.4776771469127971,-0.5084109051228789,1.163358286123176,9
produced,0.479919802776391,-0.5033405650712954,0.9995211977134678,8Highest summary of edge weights:
display(edgesStats.orderBy('sum.desc).limit(7))
edgeName,max,min,sum,count
freud,0.7194757332843367,-0.3691721677418447,45.8165427413474,370
brain,0.8077240803083802,-0.36925714175395613,31.27596725835625,159
creative,0.8075588754919899,-0.3912535625236597,30.41804556365593,153
stress,0.7456329713179576,-0.3378335788548523,25.976193255283377,107
cognitive,0.7346515989457058,-0.2768635986013295,24.798885187478785,100
creativity,0.6876949377169064,-0.4318553905309646,23.906024306364106,143
social,0.6502294554038338,-0.1882435918776268,20.51512625741932,85Lowest summary of edge weights:
display(edgesStats.orderBy('sum.asc).limit(7))
edgeName,max,min,sum,count
service,-0.02717220518964349,-0.38409168941265176,-0.6042134814366678,3
melcher,-0.16486841646031114,-0.42791377206009545,-0.5927821885204065,2
sound,-0.07704349631214606,-0.3810539051953722,-0.5881283248809397,3
portray,-0.22722479093159156,-0.30858018841481616,-0.5358049793464077,2
fuster,0.22664159560782535,-0.32616568690672787,-0.5292408380732149,8
distinctive,0.36268952837900825,-0.5584905988347715,-0.5268212152607737,4
exploration,0.17907177798380738,-0.28839304402764093,-0.521327555454355,6Finding Topics via Connections
In one of the Word2Vec2Graph model posts we showed how to find text topics with high, medium and low cosine similarities. In this post we are looking at topics around connectionsFirst, running connected components for the whole graphBrain, we can see that almost all edges are in one large connected component:
sc.setCheckpointDir("/FileStore/")
val graphBrainCC = graphBrain.
connectedComponents.
run()
val graphBrainCCCount=graphBrainCC.
groupBy("component").
count.
toDF("cc","ccCt")
display(graphBrainCCCount.orderBy('ccCt.desc).limit(7))
cc,ccCt
0,7499
403726925838,4
68719476742,2
1005022347271,2
455266533415,2
1494648619034,2
472446402592,1Next, we will create functions that are similar to functions described in the "Detect Topics in Text" post. Instead of using cosine similarity thresholds we will use edge name thresholds:
import org.apache.spark.sql.DataFrame
def w2v2gConnectionCC(graphVertices: DataFrame, graphEdges: DataFrame,
connection: String):
DataFrame = {
val graphEdgesSub= graphEdges.filter('edgeName.rlike(connection))
val graphSub = GraphFrame(graphVertices, graphEdgesSub)
sc.setCheckpointDir("/FileStore/")
val resultCC = graphSub.
connectedComponents.
run()
val resultCCcount=resultCC.
groupBy("component").
count.
toDF("cc","ccCt")
val sizeCC=resultCC.join(resultCCcount,'component==='cc).
select("id","component","ccCt").distinct
graphEdgesSub.join(sizeCC,'src==='id).
union(graphEdgesSub.join(sizeCC,'dst==='id)).
select("component","ccCt","src","dst","edgeName","edgeWeight").distinct
}
Calculate connected components with edge names similar to 'creat'
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val partitionWindow = Window.partitionBy($"component").orderBy($"edgeWeight".desc)
val result=w2v2gConnectionCC(graphBrainVertices,graphBrainEdges,"creat")
val result2 = result.withColumn("rank", rank().over(partitionWindow))
display(result2.filter("rank<4").
filter("ccCt>3").filter("ccCt<30").
orderBy("component","rank").limit(9))
component,ccCt,src,dst,edgeName,edgeWeight,rank
8,6,brain,neural,creations,0.6628680134625873,1
8,6,brain,neural,create,0.6628680134625873,1
8,6,creativity,brain,creative,0.36624866688242597,3
85899345957,4,demonstrated,productivity,creative,0.45950723748323447,1
85899345957,4,gauged,productivity,creative,0.35849743874315726,2
85899345957,4,productivity,women,creative,-0.01945508374457911,3
111669149707,7,others,people,creative,0.5717827913275904,1
111669149707,7,people,experiencing,creative,0.18518242329178428,2
111669149707,7,higher,people,creative,0.0862673194287232,3Function to convert edge ("src","dst") to .DOT language:
def cc2dot(graphComponents: DataFrame, componentId: Long): DataFrame = {
graphComponents.
filter('component===componentId).
select("src","dst").distinct.
map(s=>("\""+s(0).toString +"\" -> \""
+s(1).toString +"\""+" ;")).
toDF("dotLine")
}Connections like 'creat' - topics examples
display(cc2dot(result,670014898189L))
"measures" -> "despite" ;
"measures" -> "generally" ;
"correlates" -> "generally" ;
"generally" -> "mental" ;
"direction" -> "mental" ;
display(cc2dot(result,481036337163L))
"ability" -> "gifted" ;
"necessary" -> "ability" ;
"predicts" -> "ability" ;Connections like 'psycho' - topics examples
val partitionWindow = Window.partitionBy($"component").orderBy($"edgeWeight".desc)
val result=w2v2gConnectionCC(graphBrainVertices,graphBrainEdges,"psycho")
val result2 = result.withColumn("rank", rank().over(partitionWindow))
display(result2.filter("rank<4").
filter("ccCt>3").filter("ccCt<30").
orderBy("component","rank").limit(12))
component,ccCt,src,dst,edgeName,edgeWeight,rank
8,7,creativity,processes,psychological,0.744622420826979,1
8,7,basic,processes,psychological,0.6912580242535618,2
8,7,important,processes,psychological,0.34249288576143416,3
8589934620,10,positive,stress,psychological,0.5143877352596108,1
8589934620,10,stress,demand,psychological,0.32407394975025483,2
8589934620,10,particularly,though,psychotherapy,0.17898782193689186,3
670014898183,4,applying,methods,psychoanalytic,0.5223617540907087,1
670014898183,4,methods,investigation,psychological,0.10814820780186121,2
670014898183,4,beginning,investigation,psychoanalytic,-0.12824049313320524,3
678604832798,5,scientific,developed,psychology,0.41018382500362577,1
678604832798,5,believes,scientific,psychoanalysis,0.23228341746892528,2
678604832798,5,scientific,defined,psychology,0.10015559029020887,3display(cc2dot(result,8L))
"important" -> "processes" ;
"creativity" -> "processes" ;
"correlation" -> "creativity" ;
"basic" -> "processes" ;
"claims" -> "unsupported" ;
"claims" -> "basic" ;
display(cc2dot(result,670014898183L))
"beginning" -> "investigation" ;
"applying" -> "methods" ;
"methods" -> "investigation" ;
display(cc2dot(result,678604832798L))
"believes" -> "contained" ;
"believes" -> "scientific" ;
"scientific" -> "defined" ;
"scientific" -> "developed" ;Subgraphs based on Connections
As we can see topics built on specific connections show us more information related to these connections. Now we will build Word2Vec2Graph subgraphs based on edge names sililar to specific words.
Build subgraph with edge name like 'creat'
val subGraphBrainEdges=graphBrainEdges.filter('edgeName.rlike("creat"))
val subGraphBrain = GraphFrame(graphBrainVertices, subGraphBrainEdges)Calculate 'creat' subgraph PageRank
val subGraphBrainPageRank = subGraphBrain.
pageRank.
resetProbability(0.15).
maxIter(11).run()
display(subGraphBrainPageRank.vertices.
distinct.sort($"pagerank".desc).limit(7))
id,pagerank
insight,14.372598514419272
thinking,12.364614660701669
according,11.476433396436777
insights,9.366699097271631
expression,6.783316046665733
potential,6.546098019095852
research,6.402329517538349PageRank of subgraph like 'psycho'
val subGraphBrainEdges=graphBrainEdges.filter('edgeName.rlike("psycho"))
val subGraphBrain = GraphFrame(graphBrainVertices, subGraphBrainEdges)
val subGraphBrainPageRank = subGraphBrain.
pageRank.resetProbability(0.15).maxIter(11).run()
display(subGraphBrainPageRank.vertices.
distinct.sort($"pagerank".desc).limit(11))
id,pagerank
theory,11.854709255771983
therapy,10.320306649251734
bring,9.72775336458543
development,7.878804653398239
society,7.70065335576441
movement,7.6244138194554125
renamed,7.501048065121205
psychotherapy,7.076733495817173
treatment,6.821927165619394
science,6.821077349405393
freud,5.266755456913399Subgraphs based on Synonyms of Connections
To get more flexible view on topics around connections we will look at topics built around word2vec synonyms of connections.
Function to find word synonyms on direct Word2Vec2Graph
def w2v2gSynonyms(graphEdges: DataFrame, word: String, numSynonyms: Int):
DataFrame = {
graphEdges.filter('src===word).select("dst","edgeWeight").union(
graphEdges.filter('dst===word).select("src","edgeWeight")).
toDF("word2","weight").select("word2").distinct.
orderBy('edgeWeight.desc).limit(numSynonyms)
}Synonyms of the word 'insight':
display(w2v2gSynonyms(graphBrain.edges,"insight",7))
word2
analytical
creativity
processes
mechanisms
solutions
promote
creativeSynonyms of the word 'brain':
display(w2v2gSynonyms(graphBrain.edges,"brain",7))
word2
disorder
illness
weight
healthy
cognitive
neural
consciousnessPageRank of subgraph with connections on 5 top 'insight' synonyms
To calculate a subset of edges with connections on 'insight' synonyms we will combine edges with edge name 'insight' and edges with edge names with 5 top 'insight' synonyms.
val subGraphBrainSynonymEdges=graphBrain.edges.
join(w2v2gSynonyms(graphBrain.edges,"insight",5),'edgeName==='word2).
select("src","dst","edgeName","edgeWeight").
union(graphBrain.edges.filter('edgeName==="insight"))val subGraphBrainSynonym = GraphFrame(graphBrainVertices, subGraphBrainSynonymEdges)
val subGraphBrainSynonymPageRank = subGraphBrainSynonym.
pageRank.resetProbability(0.15).maxIter(11).run()
display(subGraphBrainSynonymPageRank.vertices.
distinct.sort($"pagerank".desc).limit(7))
id,pagerank
solutions,8.15511268601736
effect,6.5060703332388
tests,6.3660488665719415
stochastic,6.341536183190043
research,6.312647154356285
creativity,4.867181190940523
spontaneous,4.468732885667797PageRank of subgraph with connections on 7 top 'brain' synonyms
val subGraphBrainSynonymEdges=graphBrain.edges.
join(w2v2gSynonyms(graphBrain.edges,"brain",7),'edgeName==='word2).
select("src","dst","edgeName","edgeWeight").
union(graphBrain.edges.filter('edgeName==="brain"))
val subGraphBrainSynonym = GraphFrame(graphBrainVertices, subGraphBrainSynonymEdges)
val subGraphBrainSynonymPageRank = subGraphBrainSynonym.
pageRank.resetProbability(0.15).maxIter(11).run()
display(subGraphBrainSynonymPageRank.vertices.
distinct.sort($"pagerank".desc).limit(7))
id,pagerank
activity,11.333038986522027
flexibility,10.252780304836739
processes,7.7963191684322535
stimulation,7.5108416414864125
structure,7.505214528557895
psychology,7.15138848835566
neuroscience,6.692352488247509Topics based on Synonyms of Connections
The following function similar to the w2v2gConnectionCC function. It calculates connected components of subgraph built on synonyms of edge connections.
def w2v2gConnectionSynCC(graphVertices: DataFrame, graphEdges: DataFrame,
connection: String, numSynonyms: Int):
DataFrame = {
val graphEdgesSub=graphBrain.edges.
join(w2v2gSynonyms(graphBrain.edges,connection,numSynonyms),'edgeName==='word2).
select("src","dst","edgeName","edgeWeight").
union(graphBrain.edges.filter('edgeName===connection))
val graphSub = GraphFrame(graphVertices, graphEdgesSub)
sc.setCheckpointDir("/FileStore/")
val resultCC = graphSub.
connectedComponents.
run()
val resultCCcount=resultCC.
groupBy("component").
count.
toDF("cc","ccCt")
val sizeCC=resultCC.join(resultCCcount,'component==='cc).
select("id","component","ccCt").distinct
graphEdgesSub.join(sizeCC,'src==='id).
union(graphEdgesSub.join(sizeCC,'dst==='id)).
select("component","ccCt","src","dst","edgeName","edgeWeight").distinct
}Topics based on 'Brain' synonyms:
val partitionWindow = Window.partitionBy($"component").orderBy($"edgeWeight".desc)
val result=w2v2gConnectionSynCC(graphBrainVertices,graphBrainEdges,"brain",7)
val result2 = result.withColumn("rank", rank().over(partitionWindow))
display(result2.filter("rank<4").
filter("ccCt>3").filter("ccCt<30").orderBy("component","rank").limit(12))
component,ccCt,src,dst,edgeName,edgeWeight,rank
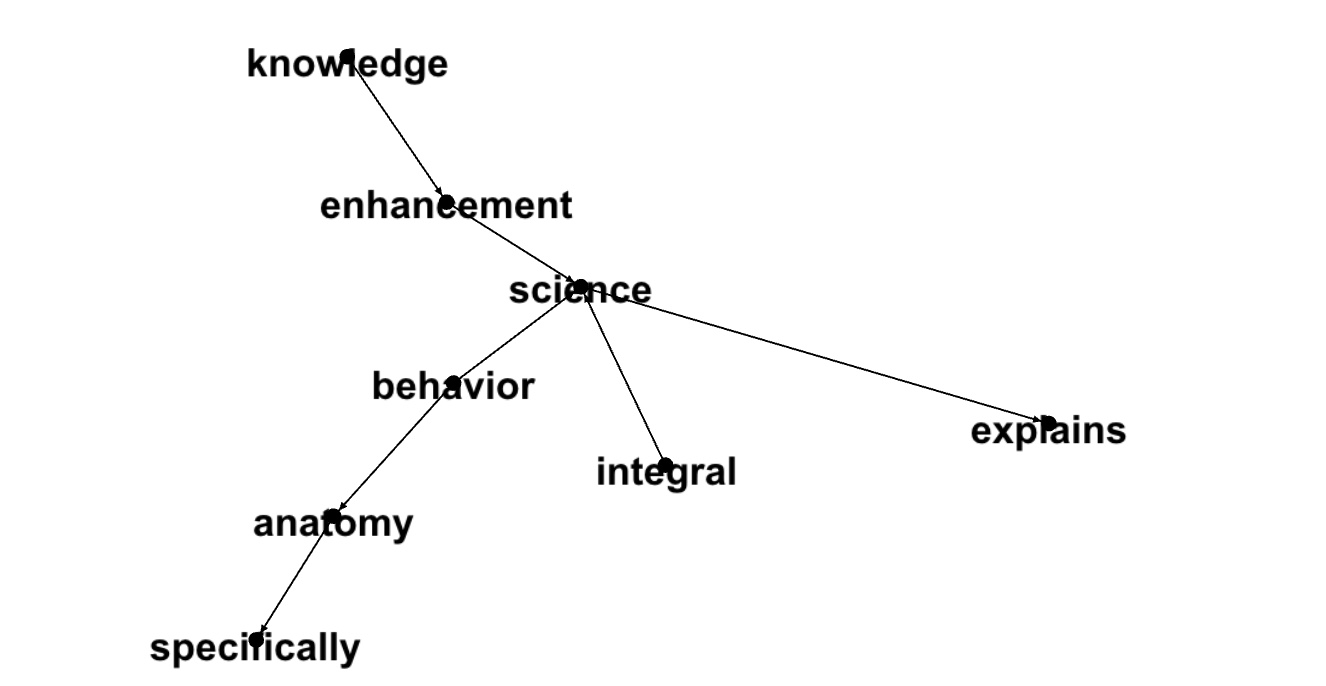
8589934597,8,science,explains,consciousness,0.3798126607701545,1
8589934597,8,behavior,anatomy,brain,0.34740929480845656,2
8589934597,8,integral,science,cognitive,0.3468999563360316,3
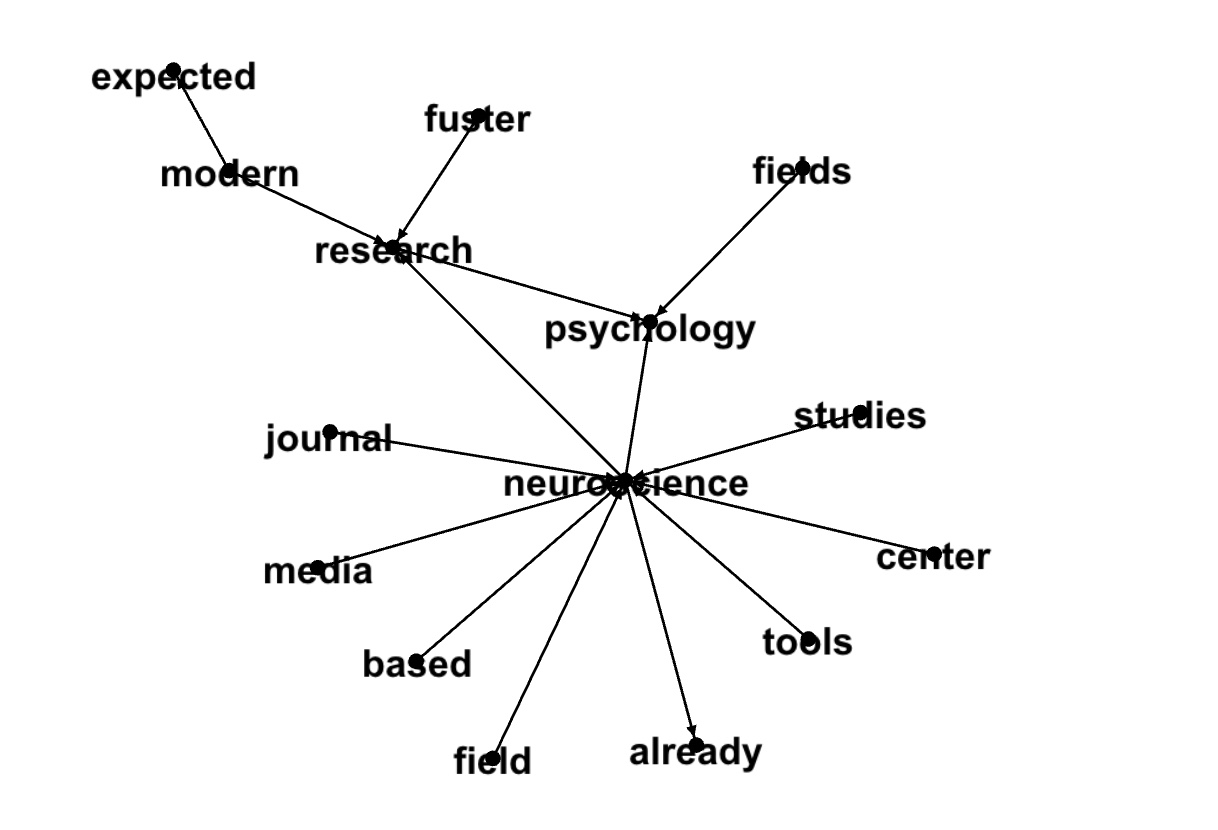
111669149711,15,studies,neuroscience,cognitive,0.6831101846837115,1
111669149711,15,neuroscience,psychology,cognitive,0.6698069278977729,2
111669149711,15,journal,neuroscience,cognitive,0.5176061843022186,3
188978561059,6,learning,memory,brain,0.5522150156892682,1
188978561059,6,memory,circuitry,cognitive,0.42575403069657436,2
188978561059,6,memory,develop,brain,0.2921438105505071,3
206158430214,13,content,distinctive,consciousness,0.5081715402806003,1
206158430214,13,distinctive,loops,neural,0.4453281580417894,2
206158430214,13,every,except,brain,0.4010585422473654,3Examples of topics based on 'Brain' synonyms edge names
'Brain' synonyms- Example 1
"recommendations" -> "learning" ;
"learning" -> "memory" ;
"memory" -> "circuitry" ;
"memory" -> "develop" ;
"develop" -> "autonomy" ;'Brain' synonyms- Example 2
"thoughts" -> "replacing" ;
"supplies" -> "energy" ;
"thoughts" -> "isolation" ;
"keeping" -> "energy" ;
"thoughts" -> "energy" ;'Brain' synonyms- Example 3
'Brain' synonyms- Example 4
Topics based on 'Insight' synonyms:
val partitionWindow = Window.partitionBy($"component").orderBy($"edgeWeight".desc)
val result=w2v2gConnectionSynCC(graphBrainVertices,graphBrainEdges,"insight",7)
val result2 = result.withColumn("rank", rank().over(partitionWindow))
display(result2.filter("rank<4").
filter("ccCt>3").filter("ccCt<30").orderBy("component","rank").limit(12))
component,ccCt,src,dst,edgeName,edgeWeight,rank
85899345930,5,fundamental,specifically,processes,0.4803744056926936,1
85899345930,5,nature,fundamental,creativity,0.4465274807724954,2
85899345930,5,nature,sciences,creativity,0.3524099120698862,3
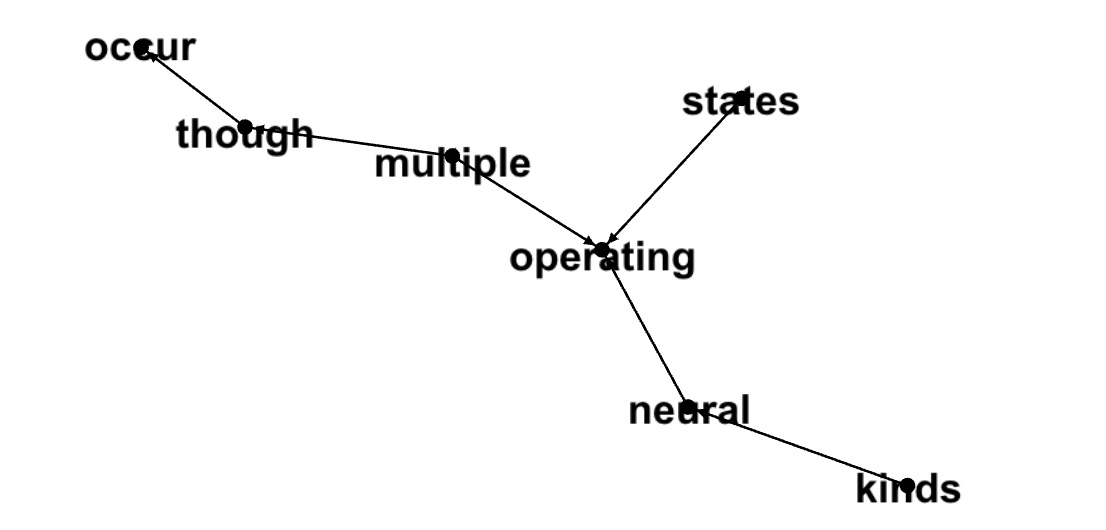
111669149718,7,kinds,neural,mechanisms,0.4834976180767224,1
111669149718,7,though,occur,insight,0.35452826011513117,2
111669149718,7,multiple,operating,processes,0.2071641265872016,3
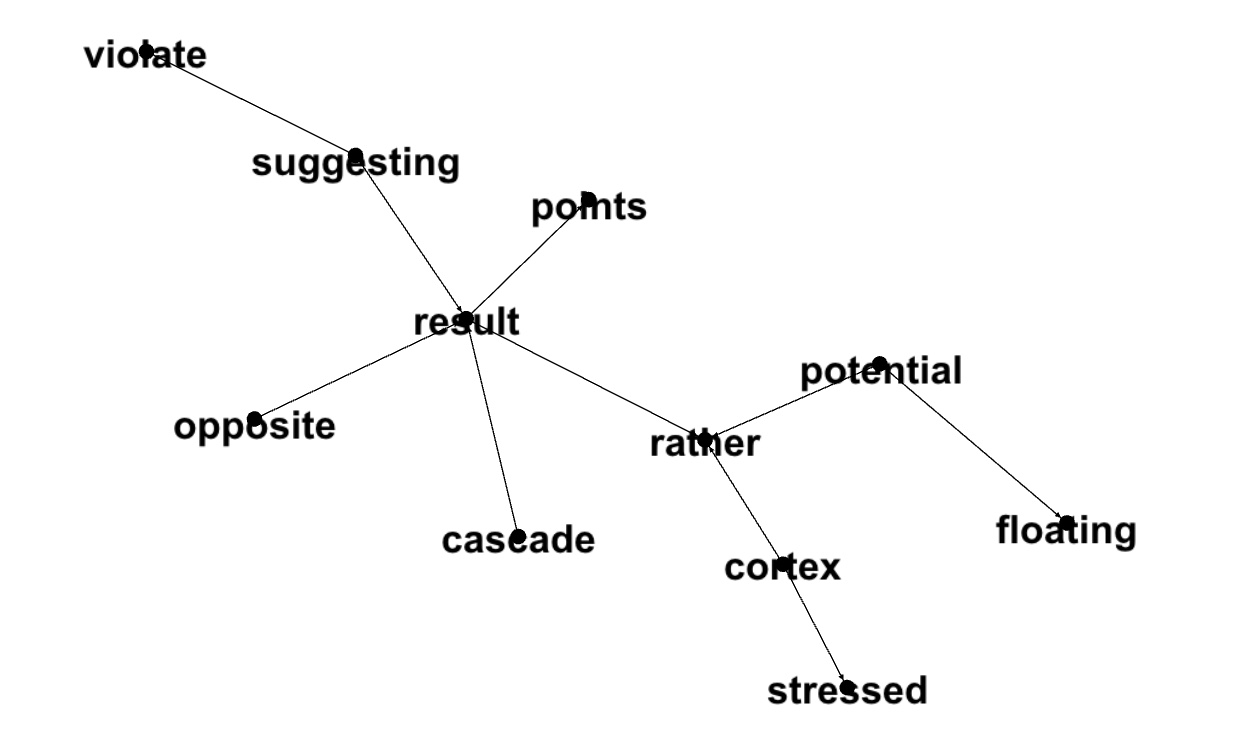
146028888099,11,cascade,result,processes,0.5347460764667417,1
146028888099,11,suggesting,violate,solutions,0.435283925113988,2
146028888099,11,potential,rather,solutions,0.4121330129010489,3
206158430215,4,executive,rehearsing,processes,0.21712514918034997,1
206158430215,4,executive,collapse,processes,0.019470471076957454,2
206158430215,4,executive,directing,processes,-0.05153457445366107,3'Insight' synonyms- Example 1
"necessary" -> "ability" ;
"predicts" -> "ability" ;
"ability" -> "gifted" ;'Insight' synonyms- Example 2
"fundamental" -> "specifically" ;
"nature" -> "conviction" ;
"nature" -> "sciences" ;
"nature" -> "fundamental" ;'Insight' synonyms- Example 3
"executive" -> "directing" ;
"executive" -> "collapse" ;
"executive" -> "rehearsing" ;'Insight' synonyms- Example 4
'Insight' synonyms- Example 5