About Word2Vec Model
Word2Vec model was created by a team lead by Tomas Mikolov in Google. In 2015 is became an open source product. Word2Vec model transforms words to vectors which gives us new insights in text analytics. Here is an excellent article about word2vec model: The amazing power of word vectors.
In our posts we will introduce a new Word2Vec2Graph model - a model that combines Word2Vec and graph functionalities. We will build graphs using words as nodes and Word2Vec cosine similarities and edge weights. Word2Vec graphs will give us new insights like top words in text file - pageRank, word topics - connected components, word neighbors - 'find' function.
Let's look at some examples of Word2Vec2Graph model based on text that describes Word2Vec model. We'll start with well known algorithm - Google pageRank. Here are top pageRank words that shows us then Word2Vec model is about words, vectors, training, and so on:
id,pagerank
words,28.97
model,25.08
vectors,20.24
training,16.32
vector,15.32
using,14.31
models,13.84
representations,9.11
example,8.28
syntactic,8.21
semantic,8.00
accuracy,7.88
results,7.23
phrases,6.82
vocabulary,6.44
neural,6.03
similar,6.01
context,5.97Spark GraphFrames 'find' function shows us which words in documents about Word2Vec model are located between the words 'words' and 'vectors'?

The next few graphs demonstrate one of well known examples about the Word2Vec model: Country - Capital associations like France - Germany + Berlin = Paris:
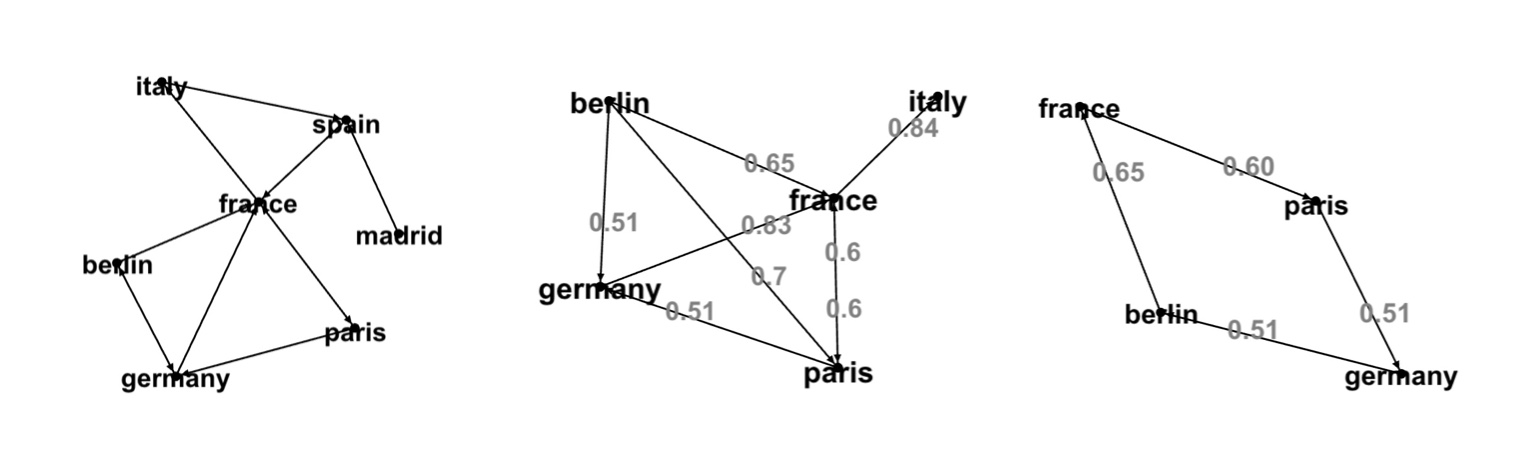
The first picture shows connected component, the second 'Germany' neighbors and neighbors of neighbors, the third a circle of word pairs. Numbers on edges are Word2Vec cosine similarities between the words.
Here are some more examples. We built a graph of words with low Word2Vec cosine similarities, ran connected components (first picture) and looked at neighbors of neighbors for the word 'vectors' (second picture):
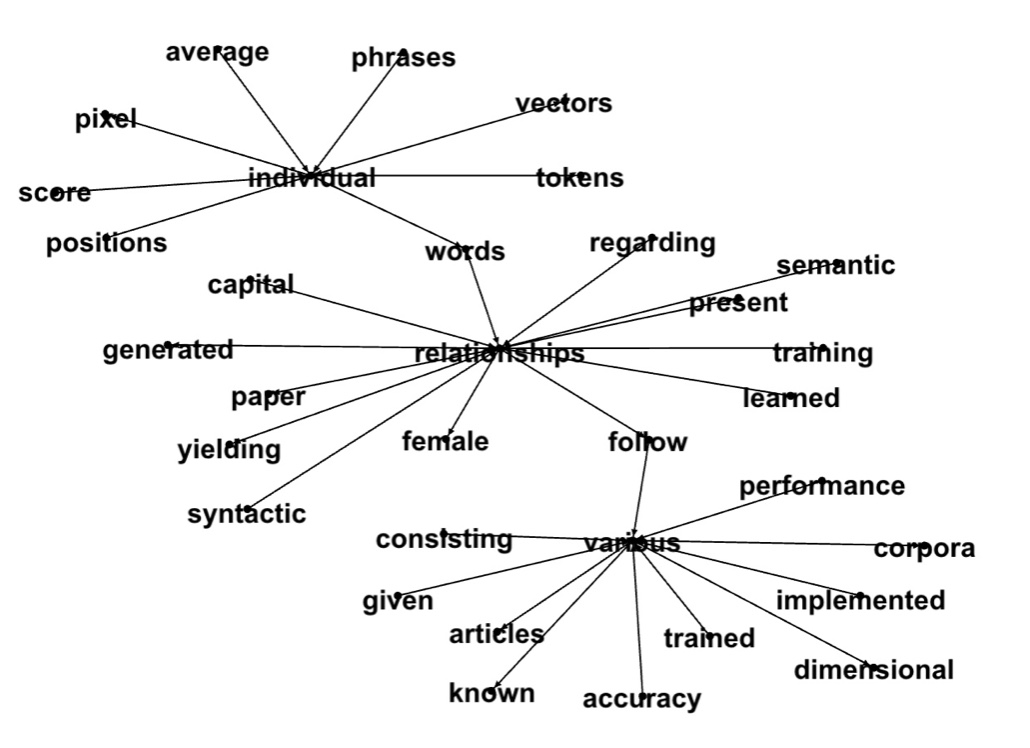
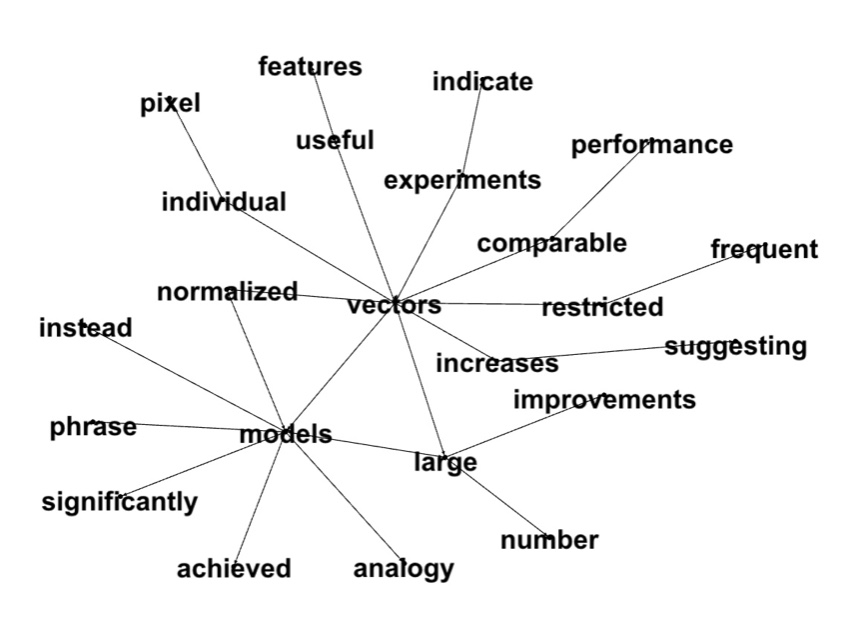
In the next several posts we will show how to build and use the Word2Vec2Graph model. As a tool we will use Spark. We will run it on Amazon Cloud via Databricks Community.
Why Spark?
Until recently there were no single processing framework that was able to solve several very different analytical problems like statistics and graphs. Spark is the first framework that can do it. It is the fundamental advantage of Spark that provides a framework for advanced analytics right out of the box. This framework includes a tool for accelerated queries, a machine learning library, and graph processing engine.
Databricks Community
Databricks community edition is an entry to Spark Big Data Analytics. It allows to create a cluster on Amazon Cloud and makes it is easy for data scientists and data engineers to write Spark code and debug it. And it's free!Training a Word2Vec Model
In our first post we will train Word2vec model in Spark and show how training corpus affects the Word2Vec model results.
AWS cluster that we run via Databricks Community is not so big. To be able to train Word2vec model we will get a 42 MB public file about news and load it to Databricks:
val inputNews=sc.
textFile("/FileStore/tables/newsTest.txt").
toDF("charLine")First we'll tokenize the data
import org.apache.spark.ml._
import org.apache.spark.ml.feature._
val tokenizer = new RegexTokenizer().
setInputCol("charLine").
setOutputCol("value").
setPattern("[^a-z]+").
setMinTokenLength(3).
setGaps(true)
val tokenizedNews = tokenizer.transform(inputNews)Then we'll train the Word2VecModel
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml._
import org.apache.spark.ml.feature.Word2VecModel
import org.apache.spark.sql.Row
val word2vec= new Word2Vec().
setInputCol("value").
setOutputCol("result")
val w2VmodelNews=word2vec.fit(tokenizedNews)Then we will save the model and we don't need to train it again.
w2VmodelNews.
write.
overwrite.
save("w2vNews")
val word2vecNews=Word2VecModel.
read.
load("w2vNews")Now let's test the model. The most popular function of Word2Vec model shows us how different words are associated:
display(word2vecNews.findSynonyms("stress",7))
word,similarity
risk,0.6505142450332642
adversely,0.6353756785392761
clots,0.6308229565620422
anxiety,0.6186497807502747
traumatic,0.6167819499969482
persistent,0.6142207980155945
problems,0.6132286190986633How Trained Corpus Affects the Word2Vec Model?
To see how the corpus that we used to train the model affects the results we will add a small file, train the model on combined corpus and compare the results.To play with data about psychology we copied it from several Wikipedia articles, got a small file (180 KB), and combined it with news file (42 MB). Then we trained the Word2vec model on this combined file.
val inputWiki=sc.textFile("/FileStore/tables/WikiTest.txt").
toDF("charLine")
val tokenizedNewsWiki = tokenizer.
transform(inputNews.
union(inputWiki))Train Word2Vec model and save the results:
val w2VmodelNewsWiki=word2vec.
fit(tokenizedNewsWiki)
w2VmodelNewsWiki.
write.
overwrite.
save("w2vNewsWiki")
val modelNewsWiki=Word2VecModel.
read.
load("w2vNewsWiki")
display(modelNewsWiki.
findSynonyms("stress",7))The results of these models are very different for some words and very similar for some other words. Here are examples:
Word: Stress - Input File: News:
word,similarity
risk,0.6505142450332642
adversely,0.6353756785392761
clots,0.6308229565620422
anxiety,0.6186497807502747
traumatic,0.6167819499969482
persistent,0.6142207980155945
problems,0.6132286190986633Input File: News + Wiki:
word,similarity
obesity,0.6602367758750916
adverse,0.6559499502182007
systemic,0.6525574326515198
averse,0.6500416994094849
risk,0.6457705497741699
detect,0.6430484652519226
infection,0.6407146453857422Word: Rain - Input File: News:
word,similarity
snow,0.8456688523292542
winds,0.800561785697937
rains,0.7878957986831665
fog,0.7052807211875916
inches,0.690990686416626
storm,0.6725252270698547
gusts,0.6721619963645935Input File: News + Wiki:
Rain News/Wiki
word,similarity
snow,0.8400915265083313
rains,0.7938879728317261
winds,0.7620705366134644
mph,0.7246450781822205
storm,0.7209596633911133
storms,0.7147307395935059
inches,0.7076087594032288Word: Specialty - Input File: News:
word,similarity
semiconductor,0.8236984014511108
diversified,0.8118916153907776
biotech,0.8052045106887817
manufacturer,0.789034903049469
maxx,0.7876819968223572
boutiques,0.785348117351532
biotechInput File: News + Wiki:
word,similarity
diversified,0.8359127640724182
titan,0.8055083751678467
automation,0.8038058876991272
machinery,0.8027305603027344
computerized,0.8011659383773804
analytics,0.8006263375282288
apparel,0.7975579500198364